Rozhraní GraphQL Národního katalogu otevřených dat
, Petr ŠkodaWebové uživatelské rozhraní Národního katalogu otevřených dat poskytuje základní vyhledávání datových sad. Nalezení datových sad od vybraného poskytovatele, či s daným klíčovým slovem je triviální úlohou. Co ale třeba získání všech datových sad, které splňují otevřenou formální normu Úřední desky? Pro efektivní vyhodnocení takového dotazu je třeba použít jiné rozhraní, například SPARQL nebo GraphQL. Co ale GraphQL vlastně je, jak vypadá dotaz v tomto jazyce a jaká data je možné získat? Právě na tyto otázky se snaží odpovědět tento článek.
O technologii GraphQL
Jazyk GraphQL byl vytvořen v roce 2012 a zveřejněn Facebookem v roce 2015. Pro zajištění neutrality dalšího rozvoje byla správa GraphQL v roce 2019 předána nadaci GraphQL. Členové této nadace pak nejen rozvíjejí specifikace GraphQL, ale přispívají do bohatého ekosystému této technologie.
GraphQL je nezávislý na konkrétním programovacím jazyku a je možné na něj nahlížet z pohledu klienta nebo z pohledu serveru. Pro klienta je GraphQL zejména dotazovacím jazykem. Z pohledu serveru se jedná o implementaci programů a knihoven, které jsou schopné provést vyhodnocení GraphQL dotazu a tedy fungovat jako tzv. GraphQL endpoint. V tomto článku se budeme věnovat hlavně druhému pohledu, tedy dotazování ze strany klienta.
Datový formát JSON
GraphQL je jazykem pro zpřístupnění dat zejména webovým aplikacím. Za tímto účelem je zcela běžné předávat data ve standardním formátu JSON. Než tedy budeme pokračovat, pojďme si krátce tento formát představit na několika příkladech, komplexnější pohled pak naleznete např. v příslušném e-learningovém kurzu.
JSON je textový formát, ale umí reprezentovat jak jednoduché hodnoty, tak i pole a kolekce klíč-hodnota. Jednoduchou hodnotou je třeba číslo, textový řetězec, či hodnota ano/ne.
Pole je pak kolekcí jednoduchých hodnot, jiných polí či objektů. V následujícím příkladu je pole, které obsahuje číslo a dva textové řetězce.
[1, "dvě", "3"]
Jak je z příkladu vidět, je možné libovolné hodnoty libovolně kombinovat.
Další konstrukcí formátu JSON je objekt.
Objekt je tvořen kolekcí dvojic klíč a hodnota, kde ke každému klíči je přiřazena právě jedna hodnota.
Klíče musí být v objektu unikátní, tedy se nemohou opakovat.
Hodnotou opět může být jednoduchá hodnota, pole nebo další objekt.
Klíčem pak může být textový řetězec.
Dobrým příkladem objektu může být třeba nákupní seznam.
V tomto seznamu máme pro každou položku uloženou informaci, jaké množství chceme koupit.
Tento seznam může vypadat následovně:
{
"banán": 3,
"mléko": 2
}
Zjevnou nevýhodou tohoto seznamu je, že není jasné co dané množství znamená. Toto je možné vyřešit třeba tím, že místo počtů použijeme objekty. Do objektů uložíme kromě informace o počtu i informaci o jednotce. Tedy zda-li chceme koupit litr mléka, jedno balení, či jeden kartón. Upravený seznam by pak mohl vypadat následovně:
{
"banán": {
"počet": 3,
"jednotka": "balení"
},
"mléko": {
"počet": 2,
"jednotka": "litry"
}
}
Složitějším příkladem je reprezentace datové sady Agendy.
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00007064/9c73b802263c5e0ccf5542f10fbc35bb",
"název": {
"česky": "Agendy"
},
"popis": {
"česky": "Agendy evidované v Registru práv a povinností ve smyslu § 51 zákona č. 111/2009 Sb. o základních registrech."
}
}
V tomto příkladu je kromě IRI datové sady možné najít také její název a popis v českém jazyce.
První dotaz v GraphQL
Zápis dotazu v GraphQL je vlastně popisem očekávané struktury výsledku. Ačkoliv by zde bylo možné citovat specifikaci, raději si ukážeme základy na několika příkladech.
Prvním příkladem je dotaz na seznam datových sad. V tomto seznamu pak chceme pro každou datovou sadu vrátit její identifikátor, neboli IRI.
query {
datasets {
data {
iri
}
}
}
Než se podíváme na výsledek, pojďme si daný dotaz rozebrat.
Na prvním řádku se pomocí klíčového slova query specifikuje, že se jedná o dotaz pro získání dat.
Použití toho klíčového slova v tomto případě není nutné.
Důvodem existence klíčového slova query je skutečnost, že GraphQL podporuje i jiné typy dotazů.
Například mutace, které je možné použít pro modifikaci dat.
V tomto článku se však jinými typy dotazů nebudeme zabývat.
Zbytek dotazu je pak specifický pro Národní katalog otevřených dat. Již od pohledu je vidět, že se budeme ptát na datové sady a jejich identifikátory.
Výsledek dotazu pak, dle aktuálního obsahu Národního katalogu otevřených dat, vypadá následovně.
{
"data": {
"datasets": {
"data": [
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006947/0f352af848d522696c0d8adc1b9f95d6"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006947/0c6cce0e6c77738d68f4e11cc1fc5084"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006947/3e5f40668f4ab122cade395a9880c542"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006947/c92eb754a516fe3faac664ff4dd1f785"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006947/c0ceba553c597d9a697d20a7fb225949"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006947/af9a9c37834114cb496fea29bd4bf7fb"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006947/fc6df4bb0668ff83f70800606e5d01a6"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006947/a77f25e1dfee2b3ec4be09f02c5fc197"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006947/d1c1bd05b7b309254bc1a6c973e8bffd"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006947/4e4762f06ca63a491efc360e793abc09"
}
]
}
}
}
Je možné si všimnout podobnosti struktury mezi dotazem a výsledkem, zejména z hlediska struktury datasets, data a iri.
Tato skutečnost není náhodná a jedná se o jednu ze základních vlastností GraphQL.
Skrze dotaz si klient vybírá ta data, která chce získat, čímž současně specifikuje strukturu odpovědi.
Tato vlastnost GraphQL umožňuje klientovi snadno získat požadovaná data v očekávané struktuře, což ulehčuje následné zpracování získaných dat.
Další důležitou vlastností GraphQL je, že ignoruje bílé znaky, například mezery a konce řádků v dotazu. Je tedy zcela na uživateli, zda-li se rozhodne dotaz vizuálně strukturovat, či se zbaví přebytečných bílých znaků za účelem snížení velikosti dotazu. Předchozí dotaz by tedy šel zapsat třeba následovně:
{datasets{data{iri}}}
Filtry v jazyce GraphQL
Výsledkem předchozích dotazů jsou údaje o deseti datových sadách. Nabízí se otázka, proč zrovna deset a jak získat informaci o zbývajících datových sadách. Odpovědí na první otázku je, že omezení velikosti výsledku na 10 datových sad je výchozím nastavením na straně serveru. Jak je možné tuto hodnotu změnit a získat datových sad ve výsledku více, či méně? Odpovědí na tuto otázkou jsou filtry.
Filtry jsou způsobem, jakým je možné v dotazu předat informace, které mají ovlivnit způsob vyhodnocení dotazu. Následující dotaz je rozšířením dotazů předchozích:
query {
datasets(offset: 2, limit: 2) {
data {
iri
}
}
}
Porovnáním s předchozím dotazem je vidět, že filtry jsou specifikovány v kulatých závorkách.
Celý dotaz ukazuje využití filtrů na objektu datasets a to konkrétně nastavením hodnot offset a limit na hodnoty 2 a 3.
V případě GraphQL pro Národní katalog otevřených dat tak dotaz přeskočí první dvě datové sady a vrátí tři následující.
Tento přístup k omezení vrácených dat je běžný pro různé dotazovací jazyky včetně jazyka SPARQL či SQL.
Jeho využití je zejména ve stránkování dat v uživatelských aplikacích.
Filtry je pak možné použít, dle specifik daného GraphQL serveru, i za jiným účelem. Na následujícím příkladu je použití filtrů k získání prvních deseti datových sad daného poskytovatele.
{
datasets (
filters: {
publisherIri: "https://rpp-opendata.egon.gov.cz/odrpp/zdroj/orgán-veřejné-moci/00007064"
}
) {
data {
iri
}
}
}
Konkrétní možnosti využití filtrů, stejně tak jako formulace zbytku dotazu, jsou omezeny konkrétním GraphQL serverem, respektive jeho schématem.
Specifika GraphQL v českém prostředí
Než se budeme věnovat tomu, odkud se data berou a na co se uživatel může ptát, je třeba zmínit několik omezení GraphQL.
Hlavní nevýhodou je omezení klíčů, které se používají ve schématu i dotazu.
Příkladem těchto klíčů z předchozího dotazu jsou hodnoty datasets, data a iri.
Použité klíče bohužel nemohou, zjednodušeně řečeno, obsahovat písmena s diakritikou.
Není tedy možné v dotazu uvést klíč název ale pouze nazev.
Nicméně v současné době existuje několik návrhů na úpravu GraphQL specifikace tak, aby bylo toto omezení odstraněno.
Toto omezení se projevilo v GraphQL schématu Národního katalogu otevřených dat. Místo “cestiny” bylo raději v definici schématu použito angličtiny. A co že je to vlastně to schéma?
GraphQL schéma
Základem každého GraphQL rozhraní je schéma, které určuje, jaké dotazy je možné vykonávat.
Z pohledu dotazů pro získání dat (query) schéma specifikuje, o jaká data a s jakými filtry si může klient požádat.
Neb by úplný popis možností specifikace GraphQL schématu vydal samostatně na několik článků, omezíme se zde pouze na nutné minimum nutné pro navigaci schématem GraphQL Národního katalogu otevřených dat.
Schéma je silně typované a mimo samotných dat umožňuje i specifikaci filtrů.
Silná typovost znamená, že je každé položce přiřazený nějaký datový typ.
Počet stránek je tedy například celé číslo, název v českém jazyce je pak textovým řetězcem.
Jak ale schéma vypadá, kde je možné ho najít a odkud se vůbec vzalo? Schéma GraphQL pro Národní katalog otevřených dat je založené na otevřené formální normě pro katalogy otevřených dat. K prozkoumání GraphQL schématu slouží tzv. introspection, která uživateli umožňuje se dotazovat na samotným schématem opět pomocí jazyka GraphQL. Samotné dotazy a jejich výsledky však nejsou snadno čitelné, důvodem je, že nejsou určeny lidem, ale aplikacím pro strojové zpracování. Pro jejich zobrazení je vhodné využít některého z bohaté sady nástrojů ekosystému kolem GraphQL.
Je tak možné využít například nástroj GraphQL Voyager pro vizualizaci schématu. Samotný nástroj nabízí, po troše klikání a kopírování, interaktivní pohled na schéma. Pro naše potřeby však stačí jeho statická verze.

Schéma je nutné prohlížet zleva doprava.
Vstupním bodem je Query ve kterém jsou definovány tři dotazy:
-
dataset- slouží k získání informací o jedné datové sadě -
datasets- slouží k získání seznamu datových sad -
datasetsWithDistribution- slouží k získání seznamu datových sad filtrovaných dle distribucí
Pro každý dotaz je na pravé straně specifikován datový typ.
Například pro datasets je to DatasetContainer.
Odpovídající šipka nás pak dovede k vizualizaci daného datového typu.
V tomto případě je to DatasetContainer, který obsahuje dva klíče data a pagination.
První klíč, data, obsahuje pole datových sad.
Druhý klíč, pagination, nese informaci o stránkování.
Pokud se na schéma pozorně podíváme, je možné v něm najít náš původní dotaz.
Tedy z levé strany skrze datasets, data, iri.
Představme si situaci, kdy bychom rádi kromě IRI datové sady získali i její název, tedy title.
Ze schématu je vidět, že title je reprezentován objektem, který má dva klíče cs a en.
Důvodem pro tuto skutečnost je, že datové sady mohou mít volitelně kromě českého názvu i název v anglickém jazyce.
S touto znalostí schématu jsme nyní schopni upravit dotaz tak, aby vracel nejen IRI, ale i název v českém jazyce.
query {
datasets {
data {
iri
title {
cs
}
}
}
}
výsledek pak může vypadat následovně:
{
"data": {
"datasets": {
"data": [
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006599/869775980",
"title": {
"cs": "IS VaVaI: Číselník stavů uplatnění výsledku VaVaI"
}
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/49370227/942853164",
"title": {
"cs": "Přehled příspěvků ČR mezinárodním organizacím v roce 2011 a 2018"
}
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00025712/90195e72c409a72df1106ffce3702c65",
"title": {
"cs": "INSPIRE téma Adresy (AD)"
}
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00025712/efb1991fdce883ba25bfcca677f6f7ad",
"title": {
"cs": "INSPIRE téma Budovy (BU)"
}
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00025712/7be8acad87b452a3f0112ecef98eb870",
"title": {
"cs": "INSPIRE téma Rozšířené Parcely (CPX)"
}
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00025712/165a95981c3f2f74d508d14c8d9fbafd",
"title": {
"cs": "INSPIRE téma Parcely (CP)"
}
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00025712/fc2a4e7bdd8df139e5bd2b168987b0ed",
"title": {
"cs": "Geometrické plány ve formátu VFK distribuované po katastrálních územích"
}
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00025712/9bc6bf4d40e1aa9aae897fc00eba3bb7",
"title": {
"cs": "Katastrální mapa ČR ve formátu DXF distribuovaná po katastrálních územích"
}
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00025712/0e58a3865c7cab329401748512694c29",
"title": {
"cs": "Katastrální mapa ČR ve formátu SHP distribuovaná po katastrálních územích"
}
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00025712/833131929f536e67688acc2bd3bf35da",
"title": {
"cs": "Katastrální mapa ČR ve formátu VFK distribuovaná po katastrálních územích"
}
}
]
}
}
}
Vizualizace schématu je vhodná pro získání celkového přehledu o tom, jaká data jsou k dispozici. Co naopak chybí, je třeba informace o filtrech.
Nástroj GraphiQL
Nabízí se tedy využití jiného, běžně používaného, nástroje GraphiQL. Tento nástroj slouží jako webový klient pro GraphQL. V případě Národního katalogu otevřených dat je možné ho najít na adrese https://data.gov.cz/graphql.
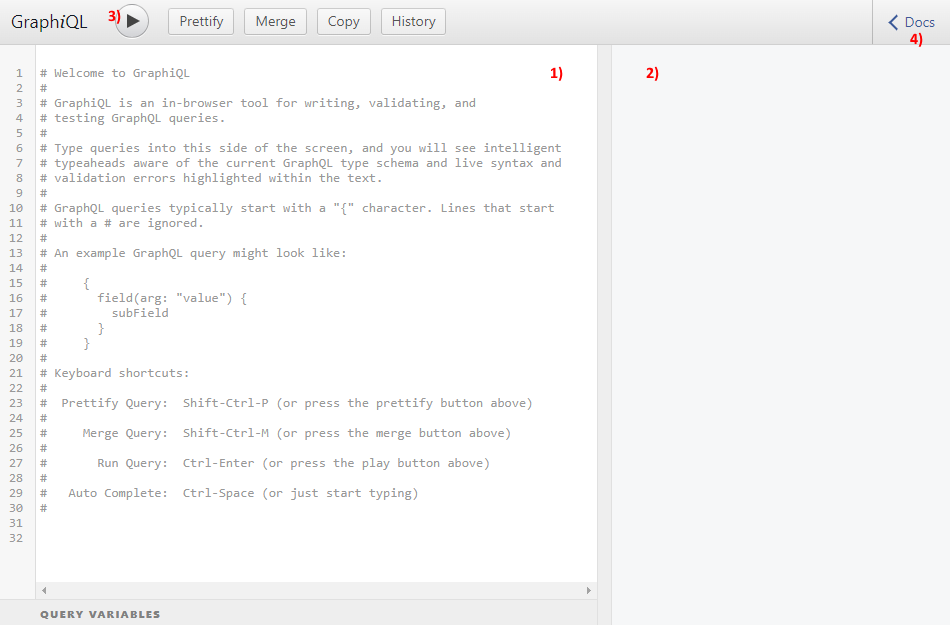
Uživatelské rozhraní nástroje se skládá z několika hlavních částí.
První částí (1) je textové pole, kam je možné vložit GraphQL dotaz.
V další části (2) je pak zobrazen výsledek dotazu.
Dotaz je možné spustit pomocí tlačítka se šipkou (3) případně kombinací kláves ctrl+enter v oblasti textového pole (1).
Poslední částí rozhraní, které se budeme věnovat, je tlačítko pro zobrazení dokumentace (4).
Po jeho stisknutí se zobrazí panel s dokumentací schématu na levé straně obrazovky.
Pojďme se nyní na tento panel (Obrázek 1) zaměřit a vysvětlit si, jak je ho možné použít k prozkoumání schématu.
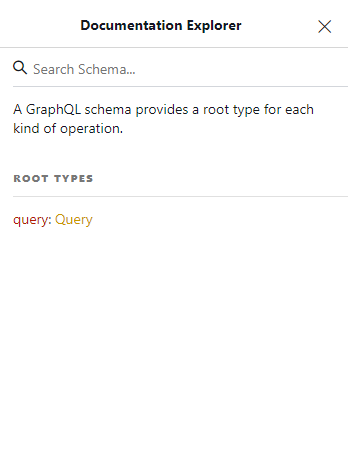
Po jeho otevření můžeme vidět seznam root types (Obrázek 1) , ve kterém je pouze jedna položka query : Query.
Zde je query klíčové slovo, které můžeme použít v dotazu.
Za dvojtečkou je pak název datového typu pro toto klíčové slovo Query.
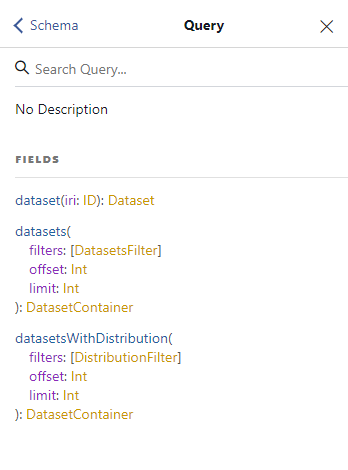
Po kliknutí na název typu se nám zobrazí hodnoty použitelné v dotazu.
V našem případě jde o seznam se třemi položkami (Obrázek 2): dataset, datasets a datasetsWithDistribution.
Zde je obsah jednotlivých položek seznamu již trochu složitější, rozeberme si tedy jeho význam na příkladu:
datasets(
filters: [DatasetsFilter]
offset: Int
limit: Int
): DatasetContainer
Na prvním řádku je název, který je možné použít v dotazu.
Ve složených závorkách následuje trojice klíčů filters, offset a limit.
Pro každý klíč je za dvojtečkou uveden datový typ.
Pro klíč filters je typem seznam DistributionFilter.
Klíče offset a ‘limit jsou typu Int, tedy celé číslo.
Po ukončení závorky je za dvojtečkou uveden "návratový" typ DatasetContainer`.
Zde je možné si kliknutím na libovolný datový typ zobrazit jeho definici.
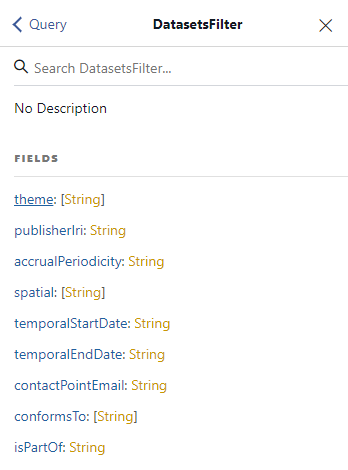
Můžeme se například kliknutím na DatasetsFilter podívat na definici obsahu filtru (Obrázek 3).
Zde si můžeme mimo jiné všimnout položky publisherIri s hodnotou string, tedy textový řetězec.
Tuto položku už jsme využili v jednom z předchozích příkladů.
Nicméně vraťme se k předchozí otázce, proč výsledek obsahuje právě 10 datových sad. Důvodem je, že server má počet deset uložen jako výchozí hodnotu pro počet datových sad, které má vrátit. Jak ale tuto hodnotu změnit?
Abychom nalezli odpověď na tuto otázku, je už třeba mít nějaké zkušenosti s dotazováním.
V takovém případě si pozorný čtenář snadno všimne hodnot limit a offset číselného typu v definici filtru pro datasets a datasetsWithDistribution.
Jak by tedy mohl vypadat dotaz, který místo 10 datových sad vrátí třeba čtyři?
Než se dostaneme k samotnému dotazu, podívejme se ještě na jednu zajímavou funkcionalitu nástroje GraphiQL.
GraphiQL nejen že umí zobrazit uživateli schéma, ale současně ho umí využít i k napovídání při psaní dotazu v textovém poli (1).
Ukažme si to na příkladu.
Pokud (1) začneme psát dotaz, máme možnost stisknutím kombinací kláves ctrl+mezerník vyvolat menu se seznamem použitelných hodnot.
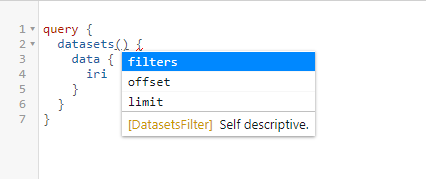
Výsledný dotaz pak může vypadat následovně:
query {
datasets(limit: 4) {
data {
iri
}
}
}
(zkusit dotaz) Výsledek dotazu pak vypadá následovně.
{
"data": {
"datasets": {
"data": [
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00006599/869775980"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/49370227/942853164"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00025712/90195e72c409a72df1106ffce3702c65"
},
{
"iri": "https://data.gov.cz/zdroj/datové-sady/00025712/efb1991fdce883ba25bfcca677f6f7ad"
}
]
}
}
}
Složitější dotaz v GraphQL
Pro demonstraci složitějšího dotazu si představme následující situaci. Jakožto uživatelé Národního katalogu otevřených dat chceme získat seznam datových sad, které obsahují data z úředních desek. Datové sady s tímto obsahem obsahují distribuce, jež deklarují kompatibilitu s OFN Úřední desky. Uživatelské rozhraní Národního katalogu otevřených dat bohužel nenabízí jednoduchou možnost, jak tyto datové sady najít. Jedním z možných řešení je položení vhodného dotazu pomocí GraphQL.
query {
datasets (
limit: 100
filters: {
conformsTo: "https://ofn.gov.cz/úřední-desky/2021-07-20/"
}
) {
data {
iri
title {
cs
}
publisher {
title {
cs
}
}
distribution {
accessURL
format
}
}
pagination {
totalCount
}
}
}
Obdoba tohoto dotazu byla použita v aplikaci úředních desek.
GraphQL nebo SPARQL
Pro úplnost je nutné připomenout, že existují i jiná řešení získání dat z NKOD než pomocí GraphQL, např. stažení dat v CSV, či položení dotazu v jazyce SPARQL. Kdy ale jaké řešení použít, je lepší SPARQL nebo GraphQL? Na podobné otázky bohužel není možné poskytnout jednoduchou univerzální odpověď. Každý ze zmiňovaných přístupů totiž cílí na jiné využití.
SPARQL je silnějším dotazovacím jazykem než GraphQL. Důvodem je nejen samotná síla jazyka, ale zejména skutečnost, že GraphQL je omezené předem daným schématem. Schéma samotné pak určuje možnosti, na které se může uživatel ptát, čímž je poměrně jasně vymezena hranice použitelnosti GraphQL. Na druhou stranu je právě pevná definice schématu jednou z výhod GraphQL oproti SPARQL. Pevné schéma a nástroje jako GraphiQL umožňují uživateli jednoduše prozkoumat možnosti rozhraní.
Dalším důležitým rozdílem je pak formát výsledku dotazu. Pro GraphQL je výsledek dotazu ve formátu JSON. Struktura je navíc definována samotným dotazem, uživatel tedy vždy ví, jaká data dostane. Tato vlastnost umožňuje snadné použití GraphQL ve webových aplikacích, což je také hlavní účel za kterým bylo navrženo. Pro SPARQL je sice možné získat výstup také ve formátu JSON, nicméně před dalším využitím je nutné provést netriviální předzpracování.
Závěr
V tomto článku jsme si krátce představili GraphQL a jeho možnosti pro získávání dat. Dále jsem si popsali schéma GraphQL rozhraní Národního katalogu otevřených dat a ukázali si jednoduchých dotazů.