Přístup k otevřeným datům: Technické překážky
Přístup přes nezabezpečený protokol HTTP či FTP
V dnešní době již neexistuje žádný argument pro poskytování obsahu na webu pomocí nezabezpečeného protokolu HTTP či ještě staršího FTP, které už v prohlížečích ztrácí podporu. Toto přirozeně platí i pro otevřená data, jakožto obsah poskytovaný přes web. Jelikož se ale jedná o běžnou součást provozu webového serveru, omezíme se na jasné doporučení: Pro svůj web, a tedy i přístup k otevřeným datům použijte protokol HTTPS. Při jeho implementaci dávejte pozor na nejčastější chyby při implementaci HTTPS popsané níže.
Výhody protokolu HTTPS
- Uživatel si může být jist, že server je ten, za který se vydává
- Uživatel si může být jist, že data, která stáhne, jsou ta, která vystavil jejich poskytovatel
- Uživatel si může být jist, že to, o která data má zájem, zůstane mezi ním a cílovým serverem (nikdo nebude sledovat jeho chování po cestě)
- Google penalizuje weby nezabezpečené pomocí HTTPS
- Nejnovější protokol HTTP/2 už nezabezpečenou variantu ani neobsahuje
Nejčastější mýty podporující nezabezpečený protokol HTTP
Jedná se o otevřená data (případně veřejný web bez přihlašování). Proč tedy obsah šifrovat?
HTTPS neslouží jen pro šifrování, tedy zajištění toho, že při přenosu dat ze serveru na klienta si jejich obsah nepřečte třetí strana. Slouží i pro ověření, že server je ten, za který se vydává. To už má smysl i v případě otevřených dat a jiného webového obsahu. Klient (uživatel) si může být jist, že data či jiný obsah není podvržen. Další argumenty naleznete na stránce Why HTTPS Matters.
Zajištění certifikátu a jeho pravidelná obnova jsou drahé
To je nesmysl. Existuje například certifikační autorita Let’s Encrypt, která certifikáty a jejich automatickou obnovu poskytuje v základní verzi zdarma. Její službu používá i tento web.
Přístup přes nedostatečně zabezpečený či chybně nakonfigurovaný protokol HTTPS
I přesto, že máte protokol HTTPS na vašem webovém serveru implementován a ve vašem oblíbeném prohlížeči při přístupu na vaše stránky či k otevřeným datům svítí v adresním řádku zelený zámeček, nemusí být vše v pořádku. Při nesprávné konfiguraci může být webový server používající protokol HTTPS náchylný k nejrůznějším zranitelnostem a nebo nemusí fungovat pro striktnější klienty. To se může projevovat například chybovými hláškami:
- unable to find valid certification path to requested target
- Invalid signature on ECDH server key exchange message
- ssl handshake failure
Jak zajistit správnou implementaci HTTPS
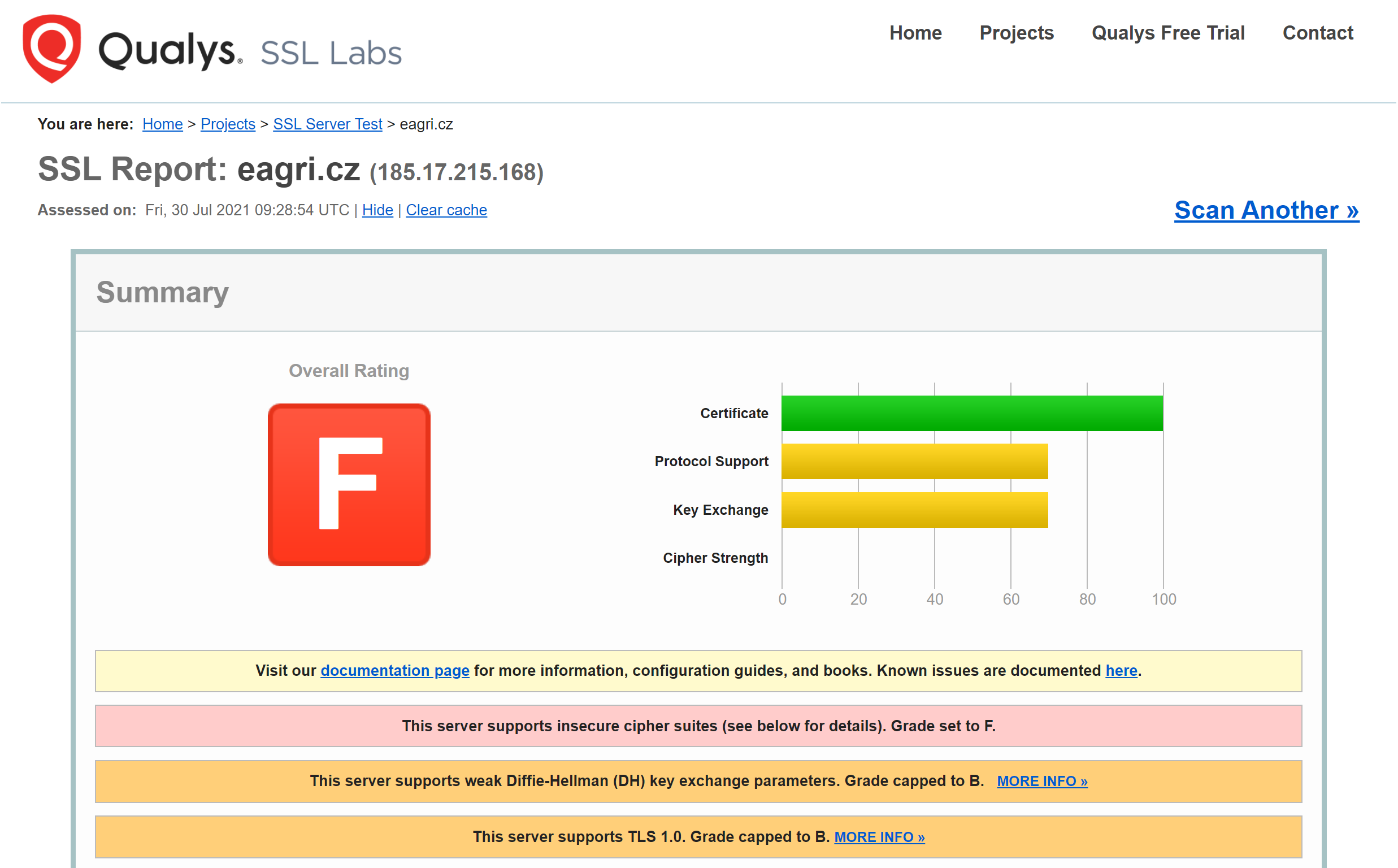
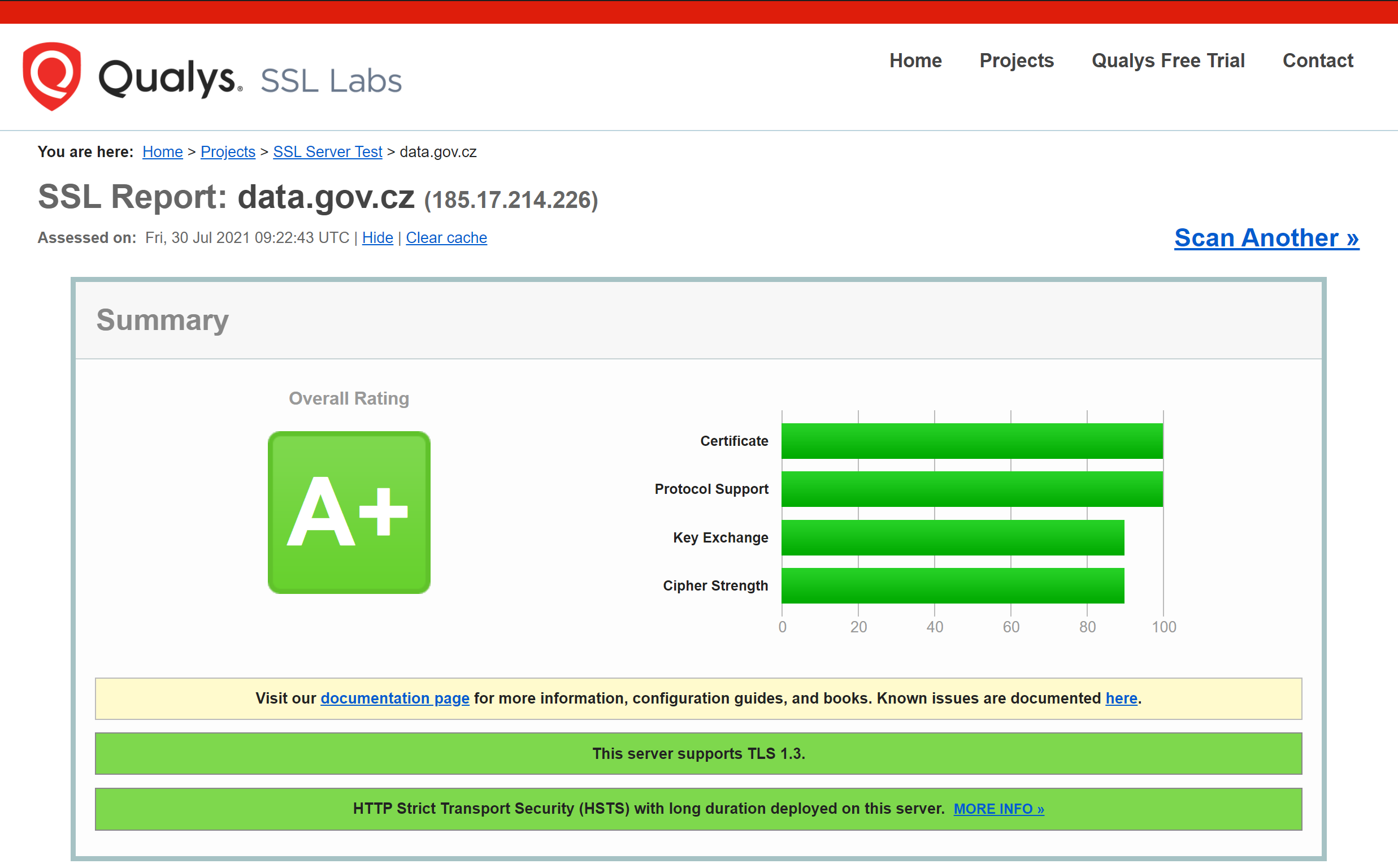
Správnou konfiguraci SSL na straně webového serveru můžete provést s pomocí nástroje Mozilla SSL Configuration Generator, který poskytuje vzorové konfigurace pro řadu webových serverů. Úroveň konfigurace volte na úrovni Modern. Pro kontrolu kvality implementace protokolu HTTPS na vašem serveru můžete použít například Qualys SSL Labs - stačí zadat vaši doménu. Snažte se dosáhnout hodnocení alespoň A, lépe však A+. Vyžadujte to případně po svých dodavatelích. Rozdíl mezi špatným a dobrým skóre je jasný:
Špatně
Dobře
Souběžná podpora HTTP a HTTPS
I při správné implementaci HTTPS je třeba rozhodnout o souběžné podpoře protokolu HTTP. Uživatel totiž typicky zadává do prohlížeče adresu bez protokolu, například data.gov.cz. Pak musí prohlížeč vědět, jak ke stránce přistoupit. Ve výchozím nastavení se prohlížeč pokusí nejprve připojit přes protokol HTTP (port 80). Toto lze řešit pouze dvěma způsoby Buďto protokol HTTP nebude podporován vůbec a doména bude zanesena to seznamu HSTS Preload, prohlížeč pak přímo použije HTTPS. Druhou možností je, že webserver bude nakonfigurován tak, že protokol HTTP bude sloužit pouze k přesměrování na protokol HTTPS.
Bez podpory HTTP, s registrací to seznamu HSTS
V této variantě webserver vůbec protokol HTTP na portu 80 nepodporuje. Pak je ale třeba doménu zanést do seznamu HSTS Preload, aby prohlížeč klienta při zadání adresy bez HTTPS věděl, že se má připojovat rovnou přes HTTPS, nikoliv HTTP, což by vedlo k chybě.
Přesměrování HTTP na HTTPS
V této variantě se libovolný požadavek na adresu přes protokol HTTP (port 80) pouze přesměruje na ekvivalentní HTTPS adresu (port 443) pomocí HTTP stavového kódu 301 Moved Permanently.
Data nejsou přístupná přes protokol IPv6
Na Internetu se používají dva základní protokoly pro přenos dat, IPv4 a IPv6. Otevřená data by měla být přístupná přes oba protokoly stejně, jako weby publikujících institucí.
Pro ústřední orgány státní správy je toto dokonce povinné, vyplývá to z řady usnesení vlády z let 2009, 2013, 2015, 2024 atd.
Ke zjištění, zda jsou data přístupná přes oba protokoly slouží například nástroj v příkazové řádce nslookup či některé online varianty:
klimek@KLIMEK-MFF-NTB:~$ nslookup www.vlada.cz
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
Name: www.vlada.cz
Address: 82.117.137.222
Name: www.vlada.cz
Address: 2001:1a48:2b::d42f:1774
Na příkladu vidíme jak IPv4 adresu 82.117.137.222, tak IPv6 adresu 2001:1a48:2b::d42f:1774.
Následující příklad ukazuje nepřítomnost IPv6 konektivity:
klimek@KLIMEK-MFF-NTB:~$ nslookup portal.cisjr.cz
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
Name: portal.cisjr.cz
Address: 85.118.129.134
Limity počtu přístupů z dané adresy
Někdy jsou rozsáhlejší datové sady zpřístupňovány jako soubory ke stažení pro jednotlivé entity, například pomocí jejich identifikátoru. To může být implementováno buďto jako dotaz do databáze, nebo jako předgenerovaný soubor pro každou entitu. Na takto zveřejněná data pak jejich poskytovatel implementuje omezení na počet přístupů za jednotku času takovým způsobem, že tím znemožní pravidelné získávání celé datové sady. Takto zveřejněná data nelze chápat jako data otevřená.
Nejčastějšími argumenty pro toto řešení bývá obava z přetížení serveru a nákladnost jiného řešení. Oba zde vyvracíme.
Cílem otevírání dat je umožnit uživatelům udržovat si jejich co nejaktuálnější kopii. Pokud jsou data poskytována pouze jako dotazy do databáze, nebo jako velké množství souborů ke stažení, uživatelům dat nezbývá nic jiného, než si pravidelně říkat o každý soubor či záznam zvlášť. To opravdu může vést k zahlcení serveru poskytovatele. Řešením ale není omezit počet přístupů, protože to nevede k cíli otevírání dat - s daty nebude moci v plném rozsahu pracovat nikdo.
Řešením je přidat alternativní způsob publikace této datové sady a poskytovat ji také jako jeden soubor ke stažení obsahující všechny záznamy. Tím dojde k radikálnímu snížení počtu dotazů a zatížení serveru - každý záznam se vygeneruje jednou, na straně poskytovatele se vloží do souboru ke stažení, a ten následně stahují uživatelé, každý jedním požadavkem. Uživatelé, kteří mají zájem o celou datovou sadu, stahují tento soubor. Uživatelé, kteří mají zájem o záznam o jedné entitě stahují dále běžným způsobem.
Tento způsob publikace lze nadále optimalizovat tím, že se bude publikovat například:
- Kompletní soubor jednou měsíčně
- Změnový soubor od začátku měsíce jednou týdně
- Změnový soubor od začátku týdne jednou denně
- Změnový soubor od začáku dne jednou za hodinu
- atd.
Tím se dosáhne toho, že si každý uživatel bude moci zvolit, jak aktuální kopii si chce udržovat, minimalizuje se zátež serveru i sítě. Navíc je toto řešení velice snadno a levně realizovatelné, typicky se jedná pouze o pravidelné spouštění dotazu nad databází.
Chybně implementovaná komprese
Cílem komprese je snížit nároky na místo na disku a na síťovou konektivitu. Při přenosu (otevřených) dat tak jistě svou roli (až na ty úplně nejmenší soubory) má, obzvláště proto, že většina otevřených formátů je textových, a texty se komprimují dobře. Dá se ovšem implementovat různě šikovnými způsoby a jednotlivé způsoby mají souvislosti i s metadatovým popisem distribucí datových sad a dokonce i se samotným dělením dat na datové sady. Jednotlivé případy si nyní rozebereme, a postupně budeme volbu komprese vylepšovat od nejméně vhodné až po nejvhodnější.
Více souborů v ZIP (nebo jiném) archivu
Tento případ je doslovné zneužití komprese k obejití toho, že nevím, jak správně dělit data na datové sady a distribuce. Je třeba důsledně oddělovat kompresi a spojení více souborů do jednoho. Na spojení více souborů do jednoho slouží i nástroj TAR, který nic nekomprimuje. Problém spočívá v tom, že jednotlivé soubory v takovém archivu již nelze jednotlivě popsat pomocí metadat, obzvláště pokud se jedná o různorodé soubory, nebo dokonce o adresářovou strukturu. Nedá se pak tedy správně popsat, v jakém formátu jaký soubor je, k čemu slouží, jaké má schéma, případně jaké má podmínky užití.
Tuto situaci je tedy třeba řešit rozdělením takové datové sady na více datových sad, kde co jeden soubor, jedna datová sada. Výjimku tvoří situace, kdy máme stejná data ve více datových formátech, například CSV a RDF, pak máme jednu datovou sadu se dvěma distribucemi, kde jedna bude CSV a druhá RDF, v obou případech bude obsahovat jeden soubor ke stažení.
Pokud by toto vedlo k neúnosně velkému počtu datových sad, je třeba zvážit, zda taková úroveň detailu dává smysl. Každopádně je třeba přidat datové sady s nižší granularitou, a tedy nižším počtem. To lze provést v různých formátech různě, pro XML lze zavést nový kořenový element a jednotlivé záznamy dát do něj, u CSV sloučit více tabulek do jedné a přidat rozlišující sloupec, u RDF stačí soubory slít.
Každopádně je třeba se dostat do situace, že distribuce datové sady má pouze jeden soubor, který není archivem jiných souborů, a pak teprve řešit kompresi.
Soubor ke stažení komprimovaný pomocí ZIP, 7z, RAR nebo jiné neproudové metody
Neproudová metoda komprese je taková, kde pro započetí dekomprese je třeba mít k dispozici celý soubor. To je v pořádku, pokud si takový soubor přinesete na USB flashce, Blu-Ray, DVD, CD. Otevřená data jsou ale poskytována přes Internet, kde nejužším hrdlem je kapacita síťového připojení. Tedy soubor se stahuje delší dobu, a může být užitečné vidět jeho obsah ještě než ho stáhnu celý.
To se běžně používá u webových stránek, kdy samotné HTML začne prohlížeč zobrazovat co nejrychleji, dříve, než je celá stránka stažena. Je totiž pravděpodobné, že uživatel začne číst odshora dolu, a čte pomaleji, než se stahuje zbytek stránky. Vidí tedy obsah dříve, než je celá stránka stažena, a často se také stane, že stránku opustí dříve, než se vůbec celá dostahuje. Tohoto efektu se ale s neproudovou kompresí nedá dosáhnout, jelikož vždy musíme čekat na stažení celého souboru, než vůbec můžeme začít s dekompresí. Proto se tyto kompresní metody do prostředí Internetu nehodí.
Soubor ke stažení explicitně komprimovaný pomocí gzip, bzip2 nebo jiné proudové metody
Proudová (streamová) metoda komprese je taková, kde mohu obsah dekomprimovat tak, jak ho načítám, jak mi přichází ze sítě, a nemusím čekat až ho dostahuju celý. Takový soubor je pak poskytnut ke stažení, a má pak typicky za jménem ještě další příponu .gz nebo .bz2, například .xml.gz, .csv.gz, .nt.gz a podobně. Pokud je ale soubor vystaven takto, klient (člověk nebo aplikace) se z hlavičky Content-Type protokolu HTTP dozví, že se jedná o data typu GNU zip. V prostředí webu se pro tyto účely používá tzv. MIME typ, v tomto případě tedy application/gzip. Nedozví se tedy už, co za datový formát je uvnitř, a když soubor stáhne, musí ho před použitím nejprve dekomprimovat správnou metodou. Takový soubor tedy lze postupně rozbalovat, ale nelze ho přímo zpracovávat. Zejména nelze takto komprimovaný datový soubor validovat vůči jeho schématu, protože validátory obvykle nedetekují kompresi a neimplementují dekompresi.
Soubor ke stažení volitelně komprimovaný pomocí gzip
Ideálním řešením v prostředí webu je využít možností, které už dlouho poskytuje protokol HTTP, a poskytovat soubor jak v komprimované, tak v nekomprimované podobě. HTTP hlavička Accept-Encoding: gzip umožňuje klientovi říct, že umí přijímat komprimovaná data. Ta jsou pak klientovi poslána v komprimované podobě, a klient si je u sebe rovnou dekomprimuje. Tentokrát je ale v odpovědi serveru jasně popsáno, kterou metodou komprimujeme Content-Encoding: gzip, a co za data se přenáší, například Content-Type: text/csv, což pak skutečně odpovídá i záznamu v katalogu jako je NKOD. Tato metoda se běžně používá pro webové stránky v HTML, CSS styly a JavaScriptové soubory, a uplně stejně lze použít i pro otevřená data. V této variantě jsou tedy data na serveru v nekomprimované podobě, a pokud klient požádá o komprimovaný přenost, server použije proudovou kompresi a klient proudovou dekompresi. Zdrojová data jsou tedy nekomprimována, cílová také a komprimovaný je pouze přenos po síti, což plní původní cíl komprese na Internetu - šetří síťovou kapacitu. V dnešní době je již disková kapacita levná, čili to, že se zdrojová data na serveru nachází v nekomprimované podobě by vadit nemělo. Tato metoda může mít jednu nevýhodu, a to že pokud k datům přistupuje více uživatelů najednou, může komprese zatěžovat procesor serveru.
Soubor ke stažení volitelně komprimovaný pomocí gzip, s předkomprimovanou verzí
Jedná se o variantu předchozí metody s tím, že na serveru jsou uloženy jak nekomprimované verze souborů, tak komprimované verze souborů. Na požadavek klienta se zašle požadovaná verze, klient nic nepozná a pracuje s konečnou, dekomprimovanou verzí dat. Soubory na serveru jsou tedy předkomprimovány, a kompresí není třeba server zatěžovat v okamžik příchodu požadavku. Například webový server nginx toto podporuje pomocí nastavení gzip_static.
Chybná hlavička HTTP Content-Type
Otevřená data se vystavují na webu a jsou přístupná typicky přes protokol HTTP(S). Ten má svá pravidla, která je pro správné fungování webu nutné dodržovat. Jedno z pravidel se týká indikace toho, jaký je formát zdroje (stránky, souboru) je přenášen. Webový server tedy v odpovědi na požadavek klienta na stažení souboru posílá nejen obsah samotný, ale i metainformace, tzv. HTTP hlavičky. Ty si můžeme zobrazit pomocí standardního nástroje curl: **curl -I
Seznam nejpoužívanějších datových typů a odpovídajících MIME typů
Úplný seznam MIME typů spravuje IANA - Autorita pro přidělování čísel (identifikátorů) na Internetu.
| Formát dat | MIME-typ |
|---|---|
| CSV soubor | text/csv |
| Schéma pro CSV dle CSV on the Web | application/csvm+json |
| Schéma pro CSV dle Table Schema | application/json |
| JSON soubor | application/json |
| Schéma pro JSON soubor | application/json |
| XML soubor s převážně strukturovaným obsahem | application/xml |
| XML soubor s převážně textovým obsahem | text/xml |
| Schéma pro XML dle XML Schema | application/xml |
| RDF soubor v serializaci Turtle | text/turtle |
| RDF soubor v serializaci TriG | application/trig |
| RDF soubor v serializaci N-Triples | application/n-triples |
| RDF soubor v serializaci N-Quads | text/turtle |
| RDF soubor v serializaci JSON-LD | application/ld+json |
| RDF soubor v serializaci RDF/XML | application/rdf+xml |
Seznam nejčastějších chybně používaných MIME typů
| Formát dat | MIME-typ |
|---|---|
| HTML stránka | text/html |
| Text | text/plain |
| Proud osmic (bajtů) | application/octet-stream |
Konfigurace webového serveru pro správnou indikaci MIME typů
Aby byl MIME typ správně indikován, je obvykle třeba korektně nastavit webový server (nginx, Apache, Microsoft IIS, …). Pokud jde o staticky poskytované soubory, používá se obvykle tabulka párující přípony souborů a MIME typy. Je třeba dát pozor na to, že soubory se stejnou příponou mohou odpovídat různým MIME typům. Například obecný JSON soubor má příponu .json stejně jako schéma pro CSV, MIME typy se ale liší. Je pak třeba vhodně strukturovat konfiguraci serveru, případně umístění souborů v souborovém systému serveru. Pokud se jedná o dynamicky poskytovaná data, hlavičku Content-Type nastvuje služba, která data generuje.
MIME typy a kódování
Otevřená data se obvykle reprezentují v textových formátech. Znaky v těchto souborech pak z pravidla používají kódování UTF-8, ale u starších XML souborů se můžeme v českém prostředí setkat s kódovaními ISO-8859-2 nebo Windows-1250. Je proto vhodné HTTP hlavičku Content-Type rozšířit o informaci indikující použité kódování, celá hlavička pak vypadá například takto: Content-Type: text/csv; charset=utf-8. Například pro webový server nginx je třeba použít v konfiguraci charset utf-8; a ujistit se, že v hodnotě charset-types je uvedeno text/csv.
Chybějící podpora Cross-Origin Resource Sharing (CORS)
Cross-Origin Resource Sharing (CORS) je technika využívající hlaviček protokolu HTTP, která umožňuje aplikacím běžícím ve webovém prohlížeči přistoupit ke zdroji (datům), který leží na jiné doméně než na které běží ona aplikace. Takový přístup je ve výchozím stavu z bezpečnostních důvodů zablokován. V kontextu otevřených dat je ale žádoucí, aby takovým aplikacím byl přístup k datům umožněn. Detailně se způsobu fungování CORS věnuje web enable-cors.org (anglicky), kde lze nalézt i příklady konfigurace pro jednotlivé webservery, či článek o CORS na webu Mozilla (anglicky).
Symptomy
Při přístupu aplikace běžící v problížeči k otevřeným datům přístupným přes webserver nepodporující CORS je tento přístup zablokován. V konzoli prohlížeče je hláška podobná této: XMLHttpRequest cannot load http://localhost:3000/example. No ‘Access-Control-Allow-Origin’ header is present on the requested resource. Origin ‘http://localhost:8080’ is therefore not allowed access..
Řešení
Pro přístup ke čtení otevřených dat se dá CORS vyřešit velmi zjednodušeně tak, že webový server bude při přístupu ke zdroji (souboru) pomocí HTTP metod GET, HEAD a OPTIONS vracet hlavičku Access-Control-Allow-Origin s hodnotou *, případně ještě hlavičku Access-Control-Allow-Methods s hodnotou GET, HEAD, OPTIONS. Pro složitější konfiguraci se řiďte webem enable-cors.org (anglicky).
Národní katalog otevřených dat kontroluje dostupnost techniky CORS metodou OPTIONS.
Strojově nečitelný formát
Strojová čitelnost souboru není dána jeho formátem (CSV, XML, JSON, …), ale způsobem využití daného formátu. Tedy i zdánlivě strojově čitelný soubor CSV může být ve skutečnosti strojově nečitelný, pokud například vznikl uložením tabulky formátované pro tisk, a tak obsahuje zbytečné prázdné řádky či odsazení.
Podobně je tomu u textových dokumentů. Strojově čitelný textový dokument umožňuje snadný strojový přístup k jednotlivým písmenům textu. Ale i takový soubor v MS Word může být úplně strojově nečitelný, když například na stránkách místo textu obsahuje obrázky textu jednotlivých stránek, což se strojově zpracovat dá jen těžko, pomocí OCR.
Jiným příkladem je soubor, který má být, ale není, CSV - není to jedna tabulka s fixním počtem sloupců, obsahuje komentáře, prázdné řádky, několik tabulek, a řadu dalších problémů:
#OPEN_EXPORT: 2020.4.14.1354
#Datum vytvoření souboru: 15.04.2020 18:52
#Stažením publikovaných dat souhlasíte s podmínkami užití těchto dat.
METADATA
Stanice ID;Jméno stanice;Začátek měření;Konec měření;Zeměpisná délka;Zeměpisná šířka;Nadmořská výška
P1PKLE01;Praha, Klementinum;01.01.1961;31.12.1993;14,4164;50,0867;190,7
P1PKLE01;Praha, Klementinum;01.01.1994;31.05.2012;14,4164;50,0867;190,7
P1PKLE01;Praha, Klementinum;01.06.2012;31.12.2019;14,416923;50,086634;190,7
PŘÍSTROJE
Přístroj;Začátek měření;Konec měření;Výška přístroje
Teploměr;01.01.1961;31.05.2012;6
Teplotní čidlo;01.06.2012;31.12.2019;6
PRVEK
Průměrná denní teplota vzduchu [T.AVG, °C]
Popis:
Hodnota - hodnota prvku
Příznak - rozšiřující informace o hodnotě
DATA
Rok;Měsíc;Den;Hodnota;Příznak
1961;01;1;,4;
1961;01;2;,3;
1961;01;3;2,2;
Data nevalidní vůči schématu
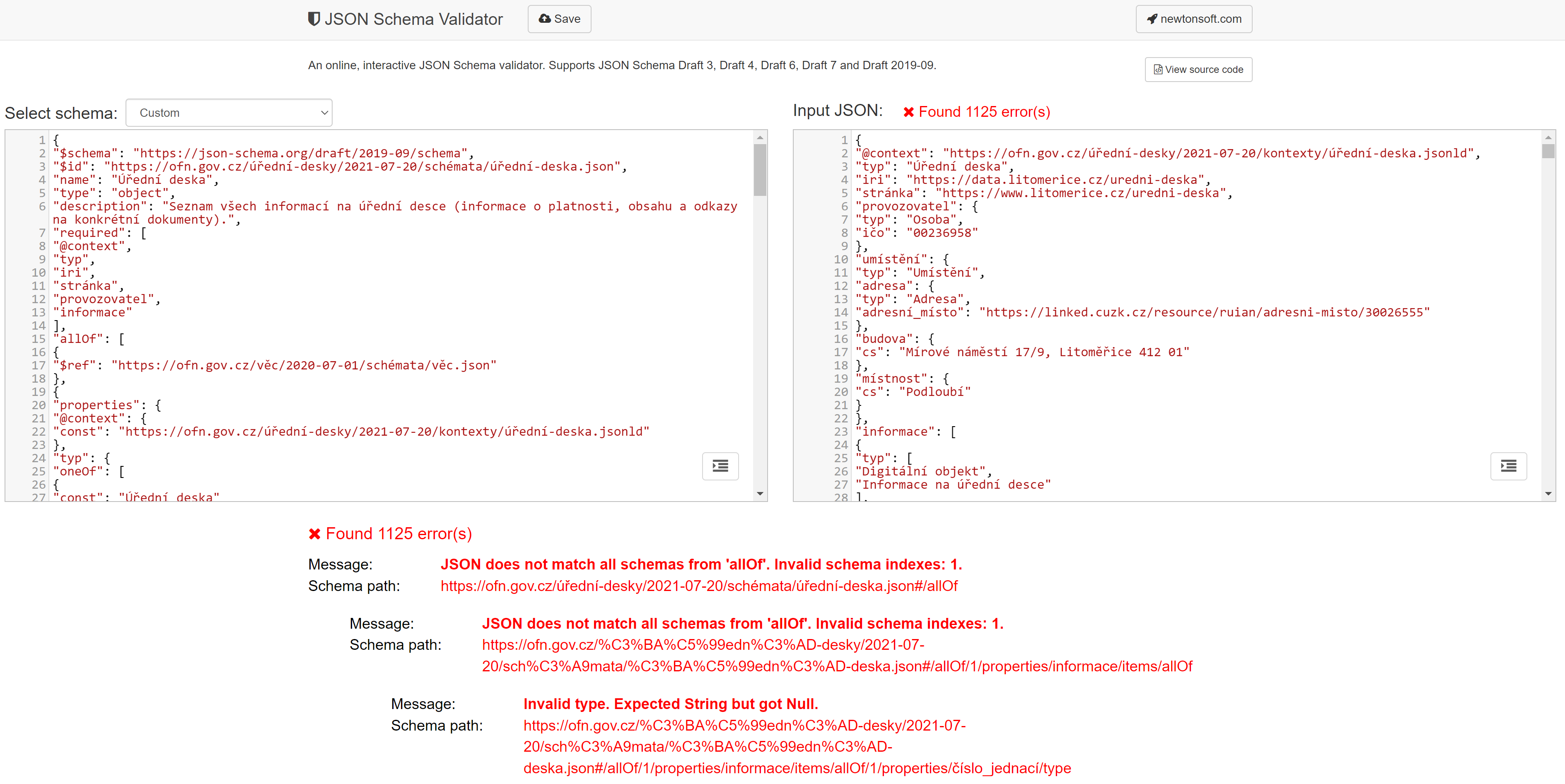
O tom, že mají být data opatřena schématem, není třeba diskutovat. V celé řadě případů ale, i když schéma existuje a je i odkazováno v metadatech datové sady v NKOD, data nejsou vůči schématu validní. To způsoje problémy jak konzumentům dat, jelikož se na schéma nemohou spolehnout, tak samotným poskytovatelům, jelikož to ukazuje problém s datovou kvalitou a s kvalitou procesu publikace dat. Národní katalog otevřených dat zatím validitu dat vůči schématu nekontroluje, je to povinnost poskytovatelů.
Nevalidní data lze odhalit jednoduše, a proces validace při publikaci dat by měl být ideálně automatizován. Validátorů, které jsou přístupné online, nebo jsou ve formě programu ke spuštění na serveru či jiném počítači, je pro otevřené formáty celá řada.
- Pro RDF popsané pomocí SHACL lze použít např. https://shacl-playground.zazuko.com/.
- Pro JSON lze využít např. https://www.jsonschemavalidator.net/ nebo https://tryjsonschematypes.appspot.com/#validate.
- Pro XML Schema lze využít např. https://www.freeformatter.com/xml-validator-xsd.html.
- Pro CSV lze využít např. https://csvw.opendata.cz/.
Příklad validace pomocí [https://www.jsonschemavalidator.net/](https://www.jsonschemavalidator.net//: