Nejčastější chyby při použití formátu CSV
Jiné kódování než UTF-8
Jediné přípustné kódování CSV souboru je UTF-8, což řeší problémy s interoperabilitou na webu, zejména pak s diakritikou a písmeny z různých abeced. Může se ale stát, že váš soubor používá jiné kódování, v českém prostředí zejména Windows-1250 či ISO-8859-2, a proto není validní.
Symptomy
Nejčastějším symptomem je chybné zobrazení diakritiky.
Ověření problému
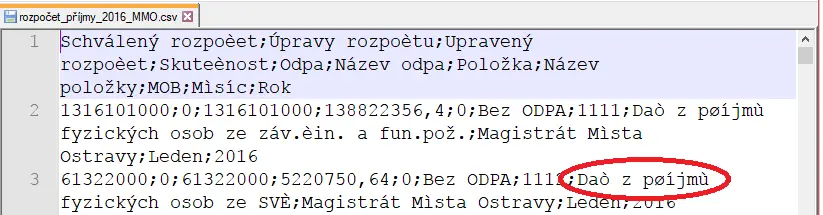
Chybné kódování lze zjistit buďto použitím validátoru, nebo také otevřením souboru textovém editoru. Na obrázku je kódování ANSI, což odpovídá ISO-8859-2.
Řešení
Je třeba zajistit, že soubor je v kódování UTF-8. To lze několika způsoby.
Správné nastavení výstupu u zdroje
Nejjednodušší je zásah u zdroje problému, tedy pokud CSV soubor exportujeme z databáze, nebo generujeme v kódu aplikace, mělo by jít nastavit UTF-8 jako výstupní kódování tam.
Konverze souboru v textovém editoru
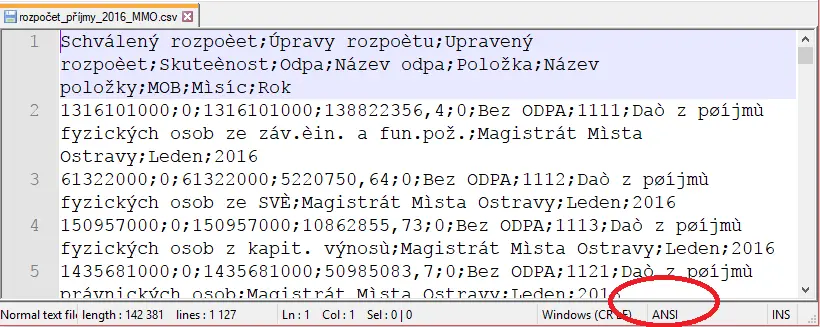
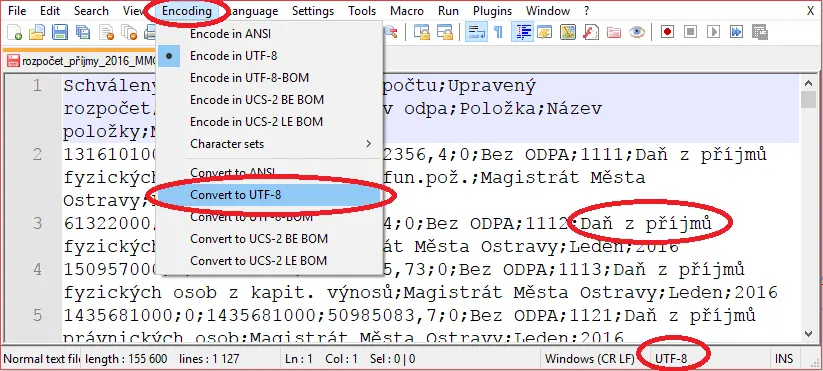
Pokud nemáme přístup ke zdroji, je třeba samotný CSV soubor překódovat, což lze například opět v textovém editoru, jak je vidět na obrázku.
Konverze z pomocí Google Sheets
Můžeme rovněž využít Google Sheets, který si s chybným kódováním poradí a nechá nás stáhnout validní CSV. Budeme potřebovat Google účet, který ale lze zřídit zdarma.
- Do Google Drive (Disk Google) nahrajeme soubor ke konverzi a otevřeme ho pomocí Google Sheets.
- Stáhneme data do CSV souboru.
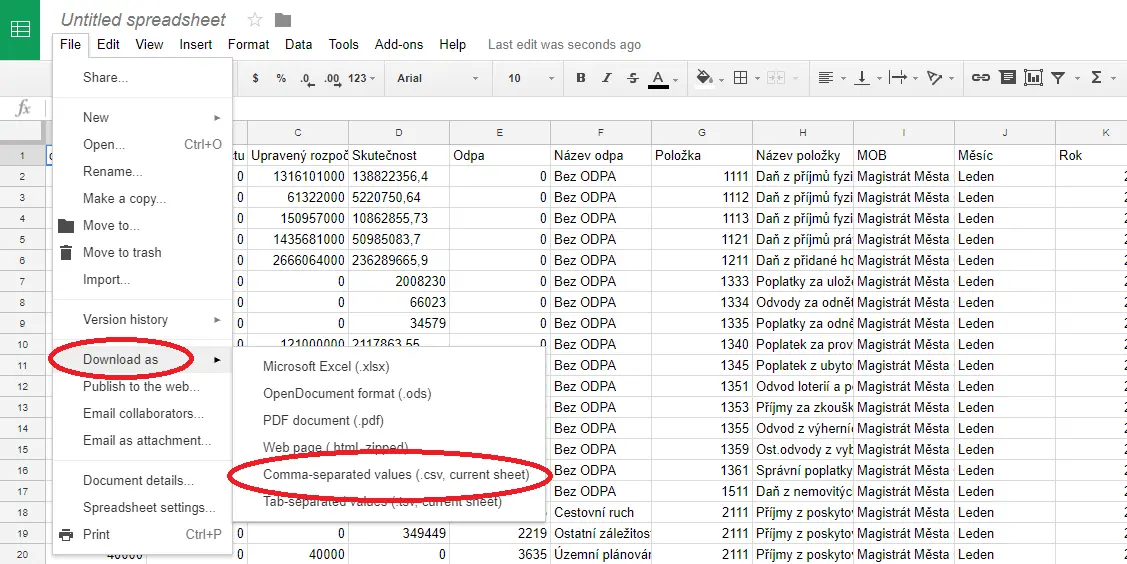
Jiný oddělovač než čárka
Jediný přípustný oddělovač údajů v CSV souboru je (jak už plyne z názvu formátu, tj. Comma Separated Values) čárka, tj. znak , s UTF-8 kódem U+002C. Může se ale stát, že váš soubor používá jiný oddělovač, v českém prostředí zejména středník ;, a proto není validní. Nejčastěji je to způsobeno tvorbou CSV souboru pomocí exportu tabulky z aplikace Microsoft Excel, která má ale podporu CSV implementovánu chybně.
Symptomy
Po otevření CSV souboru tabulkovým editorem jsou všechny údaje na řádku zobrazeny v jedné buňce.
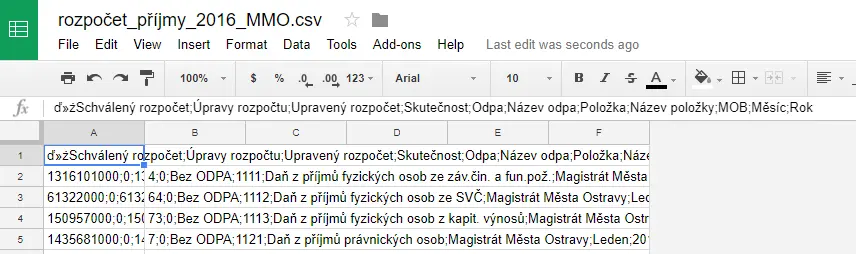
Ověření problému
Chybný oddělovač lze zjistit buďto použitím validátoru, nebo jednoduše otevřením souboru textovém editoru a vizuální kontrolou oddělovače.
Řešení
Je třeba zajistit, že soubor používá správný oddělovač, tzn. čárku ,. To lze několika způsoby.
Správné nastavení výstupu u zdroje
Nejjednodušší je zásah u zdroje problému, tedy pokud CSV soubor exportujeme z databáze, nebo generujeme v kódu aplikace, mělo by jít oddělovač nastavit na čárku.
Konverze pomocí Google Sheets pro menší soubory
Jedna z cest k validnímu CSV vede přes použití importní funkce Google Sheets, která ale funguje jen pro menší soubory. Budeme potřebovat Google účet, který ale lze zřídit zdarma.
- Z Google Drive (Disk Google) otevřeme nový Google Spreadsheet.
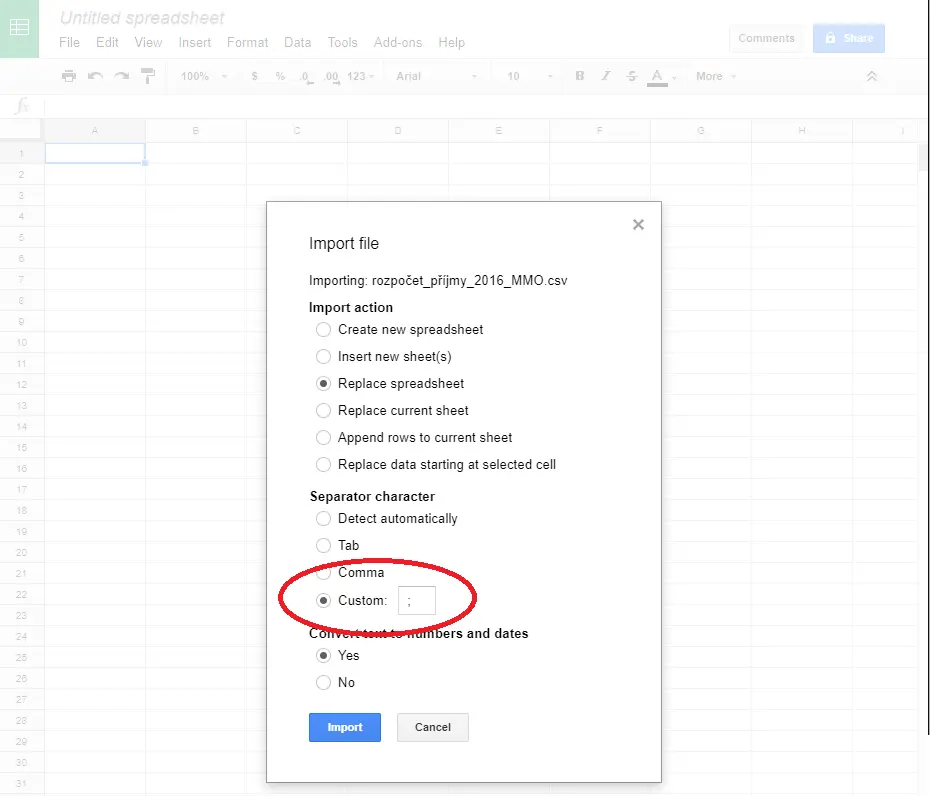
- V menu File klikneme na Import.
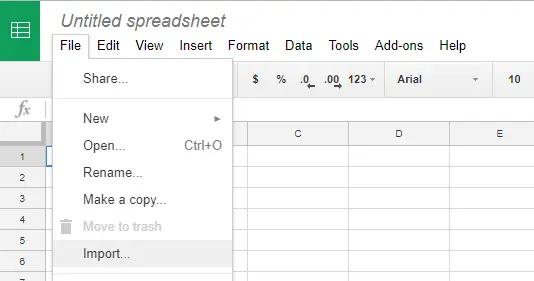
- V záložce Upload zvolíme soubor s chybným oddělovačem.
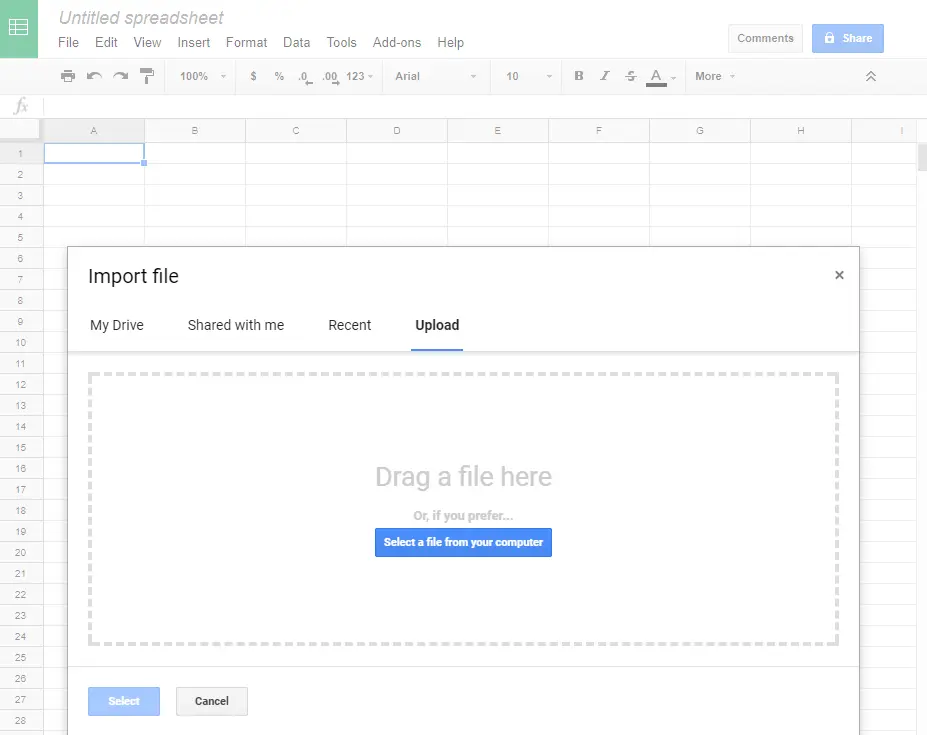
- V dialogu nastavíme oddělovač na středník ;
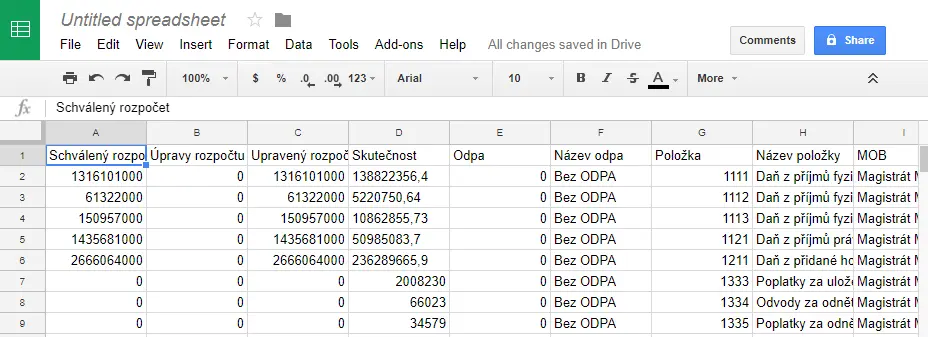
- Po doběhnutí importu máme data v Google Sheets.
- Pak můžeme data stáhnout jako validní CSV soubor.
Konverze z Microsoft Excel
Microsoft Excel má export CSV souboru chybně implementován. Jako oddělovač volí to, co má operační systém Windows nastaveno v Regionálním nastavení jako oddělovač seznamu, což je v českém prostředí středník ;. Výsledkem je tedy nevalidní soubor. Mohlo by se zdát, že řešením je tedy přenastavit toto nastavení. Řešení je to ale jen částečné, protože vzniklý soubor stejně není v kódování UTF-8 a byla by nutná další konverze. Můžeme ale rovněž využít Google Sheets jako v předešlém kroku, a to i pro velké XLS(X) soubory.
- Do Google Drive (Disk Google) nahrajeme XLS(X) soubor a otevřeme ho pomocí Google Sheets.
- Stáhneme data do CSV souboru.
Chybné escapování čárek a uvozovek
Pokud údaj v CSV souboru obsahuje čárku, je třeba celý údaj uzavřít do uvozovek. Pokud údaj obsahuje uvozovku, je jí třeba zdvojit. Tím se řeší výskyt pro CSV speciálních znaků uvnitř hodnot (tzv. „escapování“). Může se ale stát, že máte soubor, ve kterém je escapování uděláno chybně.
Symptomy
- Část souboru se zobrazuje správně, a od určitého místa je zbytek souboru vložen do jedné buňky.
- Validátor hlásí, že některý řádek souboru má jiný počet sloupců než jiný.
Řešení
Je třeba zajistit dodržování pravidel pro escapování při exportu dat do CSV. Obraťte se na dodavatele software, který data chybně exportuje. Druhou možností je v textovém editoru tyto chyby ručně detekovat a opravovat.
Mezery v zápisu čísel
Formát CSV je určen pro strojové zpracování, nikoliv pro čtení lidmi či pro tisk. Pro čísla, stejně jako pro datumy a časy se v CSV používá syntaxe pro jednoduché datové typy definované jazykem XML Schema. Stejná syntaxe se pro tyto datové typy používá i ve formátech XML, JSON a RDF, což zjednodušuje práci s nimi.
Může se ale stát, že máte CSV soubor, který používá mezery v číslech, které vznikly formátováním pro zobrazení či pro tisk, tedy například 100 000.
Symptomy
Tabulkový editor nedokáže s čísly s mezerami pracovat jako s čísly a vidí je jako text.
Řešení
Je třeba zajistit odstranění mezer z čísel. Pro celá čísla se používá syntaxe pro datový typ xsd:integer, tedy čísla bez mezer, např. 100000, záporná začínají mínusem , např. -100000.
Mezery použité pro zarovnání
V následujícím fragmentu se autor souboru soustředil na zarovnání sloupců pro jejich „hezké“ zobrazení v textovém editoru. Soubory CSV ale nejsou určeny pro pro prohlížení lidmi v textovém editoru, jsou určeny pro strojové zpracování. Nástroje pro zpracování CSV pak vidí například hodnotu 1 místo 1, a nejsou schopny hodnotu zpracovat jako číslo.
name , rank, score, probability, sas_points, surf_atoms, center_x, center_y, center_z, residue_ids, surf_atom_ids
pocket1 , 1, 8.71, 0.300, 74, 43, 9.9787, 2.8731, 21.9327, A_140 A_141 A_142 A_143 A_144 A_145 A_163 A_164 A_165 A_166 A_187 A_188 A_25 A_26 A_27 A_41 A_44 A_49, 178 179 183 191 194 307 308 309 310 311 312 332 353 354 1064 1065 1074 1075 1080 1081 1084 1085 1086 1088 1089 1097 1102 1103 1245 1249 1257 1260 1262 1264 1267 1268 1422 1423 1424 1425 1429 1431 1432
pocket2 , 2, 4.12, 0.088, 54, 27, -15.7343, -7.4354, 11.2468, A_107 A_108 A_109 A_110 A_132 A_200 A_202 A_240 A_246 A_249 A_292 A_293, 821 828 829 830 834 835 836 842 845 1006 1518 1519 1533 1853 1854 1855 1856 1903 1905 1906 1928 1929 2238 2240 2245 2246 2247
pocket3 , 3, 2.36, 0.028, 36, 21, -12.6370, 2.9140, 8.8884, A_104 A_106 A_110 A_111 A_151 A_153 A_158 A_292 A_294 A_295, 796 797 815 844 845 849 851 1140 1141 1142 1143 1156 1197 1198 2239 2240 2253 2254 2256 2258 2265
V následujícím fragmentu jsou data v sloupci Name vyplněny mezerami. Potenciálnímu uživateli to způsobí problémy, protože název nemohou použít ve svých aplikacích tak, jak je, ale musí z něj mezery nejpre odřezávat.
Id;Name;NameShort;PremiereDt;DerniereDt;TheatreId;StageId;EnsemleId
1;;Antigona ;199511 3;;231;674;
2;;Ten, který dostává políčky ;19951030;;10;638;392
3;;Nesmrtelný příběh ;19951028;;67;;
4;;Smrt v císařském domě ;199510 7;;117;;
Tento fragment navíc také obsahuje středníky místo čárek jako oddělovače, a chybný formát datumů ve sloupci TheatreId.
Správně by tedy tento fragment vypadal takto:
Id,Name,NameShort,PremiereDt,DerniereDt,TheatreId,StageId,EnsemleId
1,,Antigona,1995-11-03,,231,674,
2,,"Ten, který dostává políčky",1995-10-30,,10,638,392
3,,Nesmrtelný příběh,1995-10-28,,67,,
4,,Smrt v císařském domě,1995-10-7,,117,,
Desetinná čísla oddělená čárkou
Formát CSV je určen pro strojové zpracování, nikoliv pro čtení lidmi či pro tisk. Pro čísla, stejně jako pro datumy a časy se v CSV používá syntaxe pro jednoduché datové typy definované jazykem XML Schema. Stejná syntaxe se pro tyto datové typy používá i ve formátech XML, JSON a RDF, což zjednodušuje práci s nimi.
Může se ale stát, že máte CSV soubor, který používá jako oddělovač desetinných míst čárku 3,14, zatímco standardní oddělovač desetinných míst je tečka 3.14.
Symptomy
Tabulkový editor nedokáže s čísly s desetinnými místy oddělenými čárkou pracovat jako s čísly a vidí je jako text.
Řešení
Je třeba zajistit použití tečky jakožto oddělovače desetinných čísel. Pro desetinná čísla s pevnou desetinnou čárkou se používá syntaxe pro datový typ xsd:decimal, tedy např. 3.14, záporná začínají mínusem , např. -3.14. Pro desetinná čísla s plovoucí desetinnou čárkou se používá syntaxe pro datový typ xsd:double, tedy např. 12.78e-2.
Datumy ve formátu jiném než YYYY-MM-DD
Formát CSV je určen pro strojové zpracování dat, nikoliv pro čtení dat lidmi či pro tisk. Pro datumy a časy se, stejně jako pro čísla, v CSV používá syntaxe pro jednoduché datové typy definované jazykem XML Schema. Stejná syntaxe se pro tyto datové typy používá i ve formátech XML, JSON a RDF, což zjednodušuje práci s nimi.
Může se ale stát, že máte CSV soubor, který používá pro datumy a časy jinou syntaxi, v českém prostředí zejména 1. září 2017 nebo 9.4.2017 apod., což zbytečně znesnadňuje použití.
Symptomy
Tabulkový editor nedokáže s datumy pracovat jako s datumy a vidí je jako text nebo číslo.
Řešení
Je třeba zajistit použití správné syntaxe pro datumy a časy, tedy zjednodušeně YYYY-MM-DD pro data, HH:MM:SS pro čas, YYYY-MM-DDTHH:MM:SS pro datum a čas. Správná syntaxe pro datumy, časy a data a časy je specifikována příslušnou Otevřenou formální normou pro základní datové typy. Tedy např. 2017-09-04 pro datum bez časové zóny, 2019-01-01+01:00 pro datum s časovou zónou, 09:30:00 pro čas bez časové zóny, 09:30:10.5+01:00 pro čas s časovou zónou a pokud je specifikováno datum i čas, pak 2019-01-01T09:30:00+02:00 či 2019-01-01T09:30:10.5+01:00.
Jednotky jako součást číselné hodnoty
Hodnoty různých měření mají zpravidla své jednotky, například kilogramy, metry, roky, koruny apod. Pokud s takovými hodnotami chceme pracovat (sčítat, počítat průměry, apod.), potřebujeme je reprezentovat jako čísla. Pokud tedy poskytovatel dat zahrne textovou reprezentaci jednotek přímo do hodnoty v buňce, vznikne problém, jelikož datový typ takové hodnoty číslo není.
"Městský obvod",Kategorie,"Počet úseků","Celková délka","Celková plocha"
"PLZEŇ 1","Silnice I. třídy",49,"11025.31 m","154053.81 m2"
"PLZEŇ 1","Silnice II. třídy",17,"3410.55 m","25752.86 m2"
"PLZEŇ 1","Silnice III. třídy",16,"7095.54 m","89117.28 m2"
Správně by tedy tento kus dat vypadal buďto takto:
"Městský obvod",Kategorie,"Počet úseků","Celková délka v m","Celková plocha v m2"
"PLZEŇ 1","Silnice I. třídy",49,11025.31,154053.81
"PLZEŇ 1","Silnice II. třídy",17,3410.55,25752.86
"PLZEŇ 1","Silnice III. třídy",16,7095.54,89117.28
Nebo, ještě lépe, s využitím standardní reprezentace jednotek (m = MTR, m2 = MTK), takto:
městský_obvod,kategorie,počet_úseků,celková_délka_hodnota,celková_délka_jednotka,celková_plocha_hodnota,celková_plocha_jednotka
"PLZEŇ 1","Silnice I. třídy",49,11025.31,MTR,154053.81,MTK
"PLZEŇ 1","Silnice II. třídy",17,3410.55,MTR,25752.86,MTK
"PLZEŇ 1","Silnice III. třídy",16,7095.54,MTR,89117.28,MTK
Jednotky měření tedy mohou být například součástí názvu sloupce, nebo popisku sloupce ve schématu.
Otevřená formální norma pro částky a množství
Pro reprezentaci částek a množství existuje Otevřená formální norma Základní datové typy. Pro nejrůznější jednotky existuje jejich standardní zápis dle UN/CEFACT Common Codes a pro měny existuje Evropský číselník měn. Je třeba je používat.
Prázdné řádky či sloupce
Prázdné řádky či sloupce vznikají nejčastěji převodem formátované tabulky z tabulkového editoru (sloučené buňky, vzorce) přímo do formátu CSV. Takový obsah CSV sice může být syntakticky validní, ale znesnadňuje práci s reprezentovanými daty. Je totiž třeba nejprve zjišťovat, proč tam mezery jsou, co znamenají, zda například neoddělují součty a podobně, a pak je třeba data upravit předtím, než je možné s nimi pracovat.
Příklad: strojově nečitelné CSV - špatný oddělovač (středník), prázdné řádky, formátování pro tisk
;;;;;;;;;;;;
Back to TOC;;;;;;;;;;;;
r2 : R2. Máte v Brně trvalé bydliště (hlášené na úřadě)?;;;;;;;;;;;;
;%;počet;;;;;;;;;;
Ano;89,1%;1385;;;;;;;;;;
Ne;10,9%;169;;;;;;;;;;
CELKEM;100,0%;1554;;;;;;;;;;
"Total sample; Weight: Weight; base n = 1554";;;;;;;;;;;;
;;;;;;;;;;;;
Back to TOC;;;;;;;;;;;;
r3 : R3. Jak dlouho bydlíte v Brně? ;;;;;;;;;;;;
;%;počet;;;;;;;;;;
Řešení
Data do CSV je třeba převádět tak, aby vznikla tabulka bez děr, snadno zpracovatelná, tak, aby každý řádek obsahoval kompletní informaci o reprezentované entitě či záznamu. Pokud je zdrojem tabulka formátovaná pro tisk či pro čtení lidmi, je třeba nejprve bez újmy na obsahu:
- Odstranit formátování.
- Odstranit sloučené buňky například duplikací jejich obsahu na všechny sloučené řádky či sloupce.
- Odstranit vzorce například materializací jejich hodnot.
- Odstranit prázdné řádky či sloupce před začátkem dat.
Hodnoty null
Ve formátu CSV se prázdná hodnota reprezentuje opravdu jako prázdná. Zástupné řetězce jako například null jsou chybné - budou interpretovány jako jedna z hodnot.
Bez zřizovatele,z.ú. - Zapsaný ústav,62695487,null,495 401 565,null,"Sadová 2107,28802 Nymburk",null,null,
Řešení
Prázdné hodnoty nechte jako prázdné, tedy:
Bez zřizovatele,z.ú. - Zapsaný ústav,62695487,,495 401 565,,"Sadová 2107,28802 Nymburk",,,
Implicitní číselníky
Soubor obsahuje v některých sloupcích hodnoty z nějakého číselníku. Příkladem mohou být sloupce „Druh zřizovatele“ či „Druh sociální služby“, tedy sloupce, kde možné hodnoty jsou dány nějakým výčtem. Jedná se tedy o implicitní číselník - nikde není publikován samostatně a existuje jen jako množina hodnot použitých uvnitř jiné datové sady. Zde je třeba zvážit, zda tento číselník nepublikovat jako samostatnou datovou sadu. Pro uživatele totiž bývá zajímavé vědět, odkud se tyto hodnoty berou, jak často jsou aktualizovány, ale hlavně jaké všechny hodnoty se v této položce mohou vyskytovat. Mohou totiž existovat hodnoty, které v daném místě mohou být použity, ale v aktuálních datech se nevyskytují. Uživatel se tedy o nich nedozví, a až se v datech objeví, nebude je umět správně zpracovat. Pokud je navíc tento implicitní číselník použit ve více datových sadách, jde o další argument pro to ho publikovat jako samostatnou datovou sadu.
Řešení
Publikovat číselník jako samostatnou datovou sadu s řádnou dokumentací a metadaty. V dokumentaci původní sady by měl být na tuto novou číselníkovou datovou sadu odkaz.
Nekonzistentní hlavičky
Styl pojmenovávání sloupců v CSV by měl být konzistentní jednak v rámci jednoho souboru, ale také napříč jednotlivými publikovanými soubory. S nekonzistentní hlavčikou jako je tato:
ZRIZOVATEL_ICO,NAZEV_SLUZBY,DRUH_SOC_SLUZBY,Kapacita počet lůžek,Kapacita počet uživatelů/ intervencí,Kapacita počet uživatelů v jeden okamžik,
se pracuje velice těžko. Je třeba zvolit jeden styl pojmenovávání sloupců a toho se držet napříč všemi soubory. Pro inspiraci se podívejte na naše publikační plány.
Chybějící schéma
CSV soubor obsahuje tabulková data, a volitelně na prvním řádku hlavičku s krátkými jmény sloupců. To ale není dostatečný popis obsažených dat. Uživatel či aplikace se nedozví například datové typy údajů ve sloupcích, delší popisy sloupců, názvy sloupců ve více jazycích či další informace.
Řešení
Každý publikovaný CSV soubor by měl být opatřen svým schématem dle standardu W3C Metadata Vocabulary for Tabular Data ve formě souboru či sady souborů ve formátu JSON-LD popisujícím publikovaný CSV soubor.
Chybný datový typ sloupce
Problém nastává, když datový typ ve schématu neodpovídá typu v samotném datovém souboru. To může být způsobeno i chybným návrhem sloupce, který připouští více datových typů a tedy ani nemůže být schématem dobře popsán. Příkladem může být sloupec s popisem Datum (YYYYMMDD nebo YYYYMM nebo YYYY). Zde je jednak použit chybný typ pro datum, ale ani jeho oprava na Datum (YYYY-MM-DD nebo YYYY-MM nebo YYYY) by nepomohla, protože by sloupec stále připouštěl více datových typů. Je tedy nutno tento sloupec rozdělit na 3, povinný Rok a nepovinné Měsíc a Den.
Seznam či strukturovaná hodnota v buňce
Soubor ve formátu CSV by měl být obrazem tabulky v relační databázi, nejlépe tak, aby do ní šel přímo nahrát, a aby se s daty co nejsnadněji pracovalo. Příklad CSV souboru z datové sady „Číselníky pro volby 2016“, který porušuje základní poučku o tom, jak má vypadat databázová tabulka (první normální forma):
VSTRANA,NAZEVCELK,SLOZENI,TYPVS
299,"Koalice CZ, COEX, NEZ, ODA","013,072,088,133",K
300,"Koalice ČSNS, SV SOS","002,101",K
301,"Koalice KSČM, SZ","005,047",K
459,"Sdružení SZ, US-DEU, NK","005,080,102",D
461,"Sdružení NV, NK","080,163",D
462,"Sdružení SNK ED, SD-SN, SOS, SZ, US-DEU, NK","005,080,102,103,129,143",D
Sloupec SLOZENI totiž obsahuje čárkou oddělený seznam ID stran, které tvoří koalici. Pokud bych se tedy chtěl zeptat například na to, které strany tvoří koalici s ID „„459““, jsem odkázán na zpracovávání řetězců v databázovém jazyce místo toho, abych se zeptal zcela přirozeně pomocí tabulky vazeb mezi stranami, která by určovala příslušnost do koalice.
Jsou 2 možnosti řešení.
Dělení na 2 datové sady
Toto byly 2 datové sady, „Číselník stran pro volby 2016“ a „Příslušnost stran do koalic pro volby 2016“. CSV druhé datové sady by vypadalo třeba takto:
KOALICE,STRANA
299,013
299,072
299,088
299,133
300,002
Pro normalizaci databází se používají různě přísné normální formy. První normální forma zakazuje strukturované hodnoty, tedy například seznamy. Je to proto, že se pak s takovou hodnotou nedá rozumně pracovat, a data se musí před použitím předzpracovávat, rozpadat na více tabulek.
Duplikace řádku
Druhou možností je seznam rozpadnout do jednotlivých řádků, kde hodnoty ve zbylých sloupcích zůstanou stejné. Tomuto postupu se také říká denormalizovaná tabulka.
VSTRANA,NAZEVCELK,SLOZENI,TYPVS
299,"Koalice CZ, COEX, NEZ, ODA","013",K
299,"Koalice CZ, COEX, NEZ, ODA","072",K
299,"Koalice CZ, COEX, NEZ, ODA","088",K
299,"Koalice CZ, COEX, NEZ, ODA","133",K
300,"Koalice ČSNS, SV SOS","002",K
300,"Koalice ČSNS, SV SOS","101",K
Chybná hlavička HTTP Content-Type u CSV souboru
I u CSV souboru se správným kódováním UTF-8 vystaveném na webu se může stát, že se diakritika v takovém souboru v prohlížeči nebude zobrazovat správně. Pravděpodobně je na vině špatná HTTP hlavička Content-Type v odpovědi se souborem, která by správně měla kódování obsahovat: Content-Type: text/csv; charset=utf-8. Vyskytují se ale případy, kdy v hodnotě kódování chybí, tj. Content-Type: text/csv, a tedy prohlížeč neví, že má zobrazovat kódování UTF-8, a nebo je dokonce indikován špatný typ, například Content-Type: text/plain nebo Content-Type: application/octet-stream. Obecnější informace o tomto tématu naleznete v sekci na téma Chybná hlavička HTTP Content-Type.
Řešení
Je třeba nakonfigurovat webový server tak, aby soubory CSV poskytoval se správnou hlavičkou, tj. Content-Type: text/csv;charset=utf-8;header=present v případě CSV s hlavičkou a Content-Type: text/csv;charset=utf-8;header=absent v případě CSV bez hlavičky, které ale nedoporučujeme používat. Například pro webový server nginx je třeba použít v konfiguraci types { „text/csv;charset=utf-8;header=present“ csv; } - uvozovka zde má být běžná dvojitá uvozovka, nikoliv horní a dolní.
Data nevalidní vůči schématu
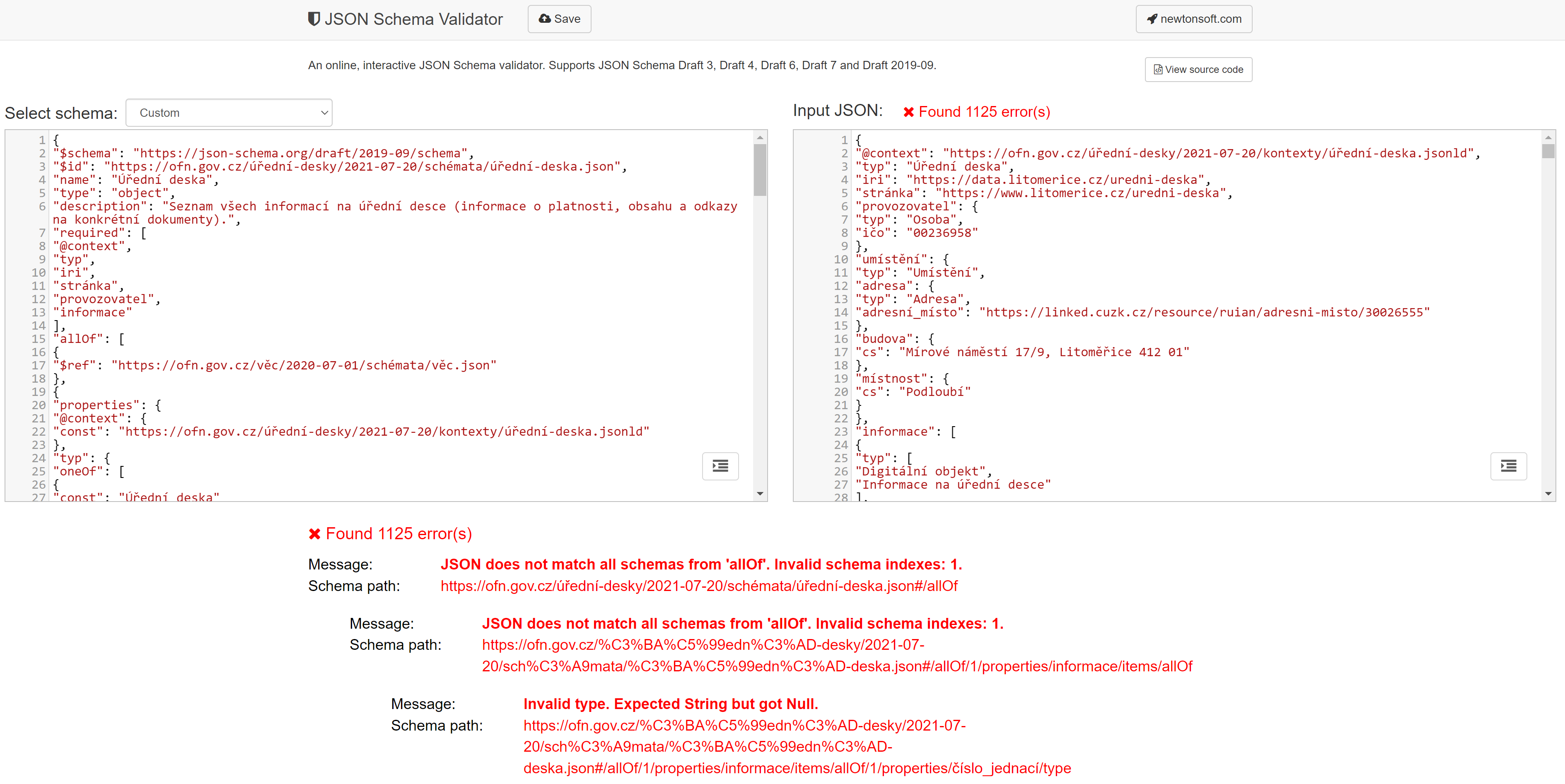
O tom, že mají být data opatřena schématem, není třeba diskutovat. V celé řadě případů ale, i když schéma existuje a je i odkazováno v metadatech datové sady v NKOD, data nejsou vůči schématu validní. To způsoje problémy jak konzumentům dat, jelikož se na schéma nemohou spolehnout, tak samotným poskytovatelům, jelikož to ukazuje problém s datovou kvalitou a s kvalitou procesu publikace dat. Národní katalog otevřených dat zatím validitu dat vůči schématu nekontroluje, je to povinnost poskytovatelů.
Nevalidní data lze odhalit jednoduše, a proces validace při publikaci dat by měl být ideálně automatizován. Validátorů, které jsou přístupné online, nebo jsou ve formě programu ke spuštění na serveru či jiném počítači, je pro otevřené formáty celá řada.
- Pro RDF popsané pomocí SHACL lze použít např. https://shacl-playground.zazuko.com/.
- Pro JSON lze využít např. https://www.jsonschemavalidator.net/ nebo https://tryjsonschematypes.appspot.com/#validate.
- Pro XML Schema lze využít např. https://www.freeformatter.com/xml-validator-xsd.html.
- Pro CSV lze využít např. https://csvw.opendata.cz/.
Příklad validace pomocí https://www.jsonschemavalidator.net/: