Volební mapa ČR - volby 2021
, Michal ŠkopAš a Kraslice jsou na západním konci ČR, Karviná s Orlovou na východním. Přesto volebním chováním jsou na společném extrému v rámci ČR. Detailní klasické geografické mapy s volebními výsledky jsou již tradiční součástí volebního servisu médií. Ukážeme si proto podrobnější analýzu výsledků parlamentních voleb 2021 za pomoci otevřených dat - cílem je mapa ČR, ale ne klasická geografická, nýbrž “volební”.
Klasická volební mapa s výsledky voleb po jednotlivých okrscích tentokrát vznikla v několika médiích: Mj. ji zveřejnil Deník, iRozhlas nebo Seznam Zprávy. Postup, jak na takovéto mapy, lze najít ve starším článku Mapa s výsledky voleb po okrscích.
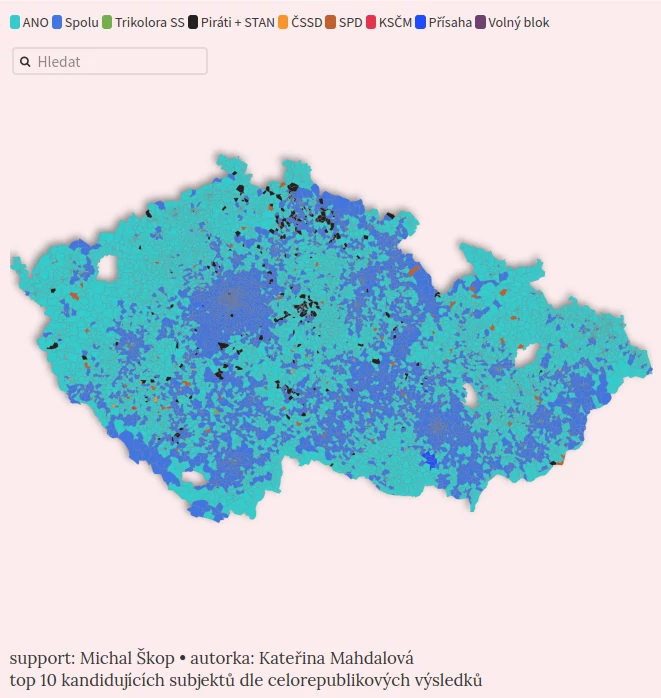
Výsledek: Volební mapa ČR dle toho, jak lidé v jednotlivých regionech volí
“Klasická” geografická mapa vs. “volební mapa”
Při podrobnější analýze výsledků voleb si můžeme položit otázku, jak je ČR rozdělená dle toho, koho lidé v jednotlivých regionech volí. Takovouto nebo podobné otázky lze zodpovědět díky otevřených datům.
Získáme tím jinou “mapu” než klasickou geografickou. Na geografické mapě jsou u sebe místa, která jsou u sebe blízko v realitě. Jako třeba Aš a Kraslice nebo Karviná a Orlová. Daleko od sebe jsou místa, mezi kterými musíte urazit velkou vzdálenost - jako z Aše do Karviné. Na geografické mapě ČR jsou tedy na jednom konci Aš a Kraslice a na druhém Karviná a Orlová, někde mezi nimi např. Praha a Brno.
V naší “volební mapě” ale budou u sebe místa, kde lidé volí obdobně. Najednou budou Aš, Kraslice, Karviná i Orlová blízko u sebe, protože lidé tam volí velmi podobně. A výsledky voleb se tam velmi liší třeba od Prahy nebo Brna. V rámci ČR budou Aš, Kraslice, Karviná i Orlová na jednom konci a Praha a Brno na druhém.
Obdobná mapa byla publikována na Investigace.cz.
Použijeme analytické metody, které co nejlépe vystihnou v dvourozměrném prostoru (“2D mapa”) rozdíly mezi jednotlivými volebními okrsky (obcemi, okresy, atd.) a zároveň i mezi jednotlivými kandidujícími stranami.
Tato analýza v případě parlamentních voleb 2021 ukazuje to, že hlavní rozdíl u větších stran ve volebním zisku v jednotlivých volebních okrscích byl: obě koalice (SPOLU a PirSTAN) vs. ANO + SPD. Tedy zjednodušeně, pokud v nějakém okrsku měla koalice SPOLU nadprůměrný zisk, spíše tam měl nadprůměrný zisk i PirSTAN. A obdobně to platilo pro dvojici ANO, SPD. Což tedy představuje osu X v naší “mapě”.
Osa Y je zhruba dělení SPOLU a ANO vs. PirSTAN a SPD. Další osy by vystihovaly např. větší nebo menší zisky ČSSD a Přísahy. Ale pro jednoduchost nám stačí osy dvě.
Obce s rozšířenou působností

Na první pohled vidíme, že extrémy z hlediska volebního chování jsou v ČR na jedné straně části Moravskoslezského, Ústeckého a Karlovarského kraje (obecně více ANO, SPD) vs. Praha a nejbližší okolí na straně druhé (více SPOLU a PirSTAN).
Městské části
Takovýto model nám umožní se podívat na různé úrovně geografické - od jednotlivých volebních okrsků po kraje nebo NUTS2. Jako příklad se můžeme podívat na města, která jsou při volbách dělená na městské obvody. Zde např. jasně vystupují na straně ANO+SPD okrajovější sídliště v rámci jednotlivých velkých měst (Ostrava-Jih, Neštěmice a Severní terasa v Ústí nad Labem, Plzeň 1 (Bolevec), Starý Lískovec nebo Kohoutovice v Brně, Praha 11 a Praha 12 v rámci Prahy). Na druhou stranu potom centra volila více obě koalice (Moravská Ostrava a Přívoz, Ústí nad Labem-město, Plzeň 2 (Slovany) a 3 (centrum a Bory), Brno-střed, Praha 1, 2, 3, 5, 6 a 7 v rámci Prahy).
Lze takto udělat např. i meziměstská srovnání: Brno-střed volí podobně jako Praha 3, nejvíce “pro-koaliční” číst Plzně (Plzeň 2 - Slovany) jako nejméně “pro-koaliční” část Prahy (Praha 11 a 12), Ostrava-Jih podobně jako Nestěmice a Severní terasa v Ústí nad Labem.

Použitá data
Data použitá pro tento projekt si najdeme v NKOD - Národním katalogu otevřených dat:
- Pro data o volebních výsledcích použijeme data ČSÚ: Volební výsledky.
- Číselníky k regionům opět zveřejňuje ČSÚ: Číselníky regionů (zde ORP).
Postup zpracování
Analytická metoda
Jako základ je použito klasické multidimensionální škálování a analýza hlavních komponent, kde základ jsou výsledky voleb v jednotlivých volebních okrscích.
Příprava dat
V této fázi si připravíme základní tabulku, kde na každém řádku budou informace o výsledku hlasování v jednom volebním okrsku spolu se všemi doplňujícími geografickými informacemi o tomto okrsku (obec, ORP, okres, kraj, příp. městské části u měst, které se dělí na volební obvody).
Jako vstup použijeme otevřená data o výsledku voleb po okrscích. Jedinou výjimkou jsou zde informace o ORP (obce s rozšířenou působností), které v těchto datech nejsou, jejich názvy získáme přímo z číselníku těchto obcí také od ČSÚ.
Postup v jazyce Python je zde a výpočet matice vzdáleností zde.
Výpočet modelu
Nejprve spočteme matici vzdáleností jednotlivých volebních okrsků. Zde nevybereme všechny volební okrsky (více jak 14 000), ale stačí nám jejich náhodný vzorek (záleží, jakou chceme přesnost, ale 1000 a více by mělo být dostačující pro většinu aplikací). Tím vyřešíme dva problémy jednou ranou:
- Problém nestejně velkých okrsků (několikatisícové městské okrsky vs. desítky voličů na malých vesnicích) - náhodný vzorek lze vybrat tak, aby pravděpodobnost výběru volebního okrsku do vzorku odpovídala počtu voličů ve volebním okrsku (např. tisícový okrsek má 10x vyšší šanci na zařazení do vzorku než okrsek se sto voliči).
- velká velikost prvotní matice vzdáleností (14000 x 14000 je často hodně náročné na paměť i čas, např. i jen 7000 x 7000 je minimálně 4x rychlejší)
Spočteme souřadnice tohoto vzorku pomocí multidimensionálního škálování. Do tohoto prostoru jsou následně promítnuty strany (získáme souřadnice stran). A do takto získaného prostoru politických stran lze potom zase promítat nejrůznější skupiny volebních okrsků pomocí metody hlavních komponent (např. geografické skupiny: obce, ORP, okresy, kraje - získáme jejich souřadnice).
Tento postup využívá toho, že multidimensionální škálování má matematickou souvislost s analýzou hlavních komponent a lze je takto kombinovat.
Zobrazení grafu (“volební mapy”)
Samotné zobrazení lze udělat mnoha způsoby, typicky v tabulkových procesorech (Excel, Libre Office, Google Sheets). Zde používám zobrazení přímo názvů jednotlivých ORP za pomoci HTML s javascriptovou knihovnou D3.
Barevné rozlišení je dle NUTS 2.
Další
Tento článek ukazuje, že otevřená data o volbách v kombinaci s dalšími otevřenými zdroji umožňují i další detailnější analýzy, které jdou nad základní popis volebních výsledků.
Takové analýzy mohou být použité v akademickém výzkumu či výuce, ale i komerčně v médiích nebo např. v politickém marketingu.
Použité nástroje a zdroje
Závěr
Článek ukazuje jednu z metod, jak detailněji analyzovat volební výsledky na různých geografických úrovních od volebních okrsků po kraje. Zároveň demonstruje, jak používat volební a další otevřená data ČSÚ.