Kartogram ČR (choropleth, choropletová mapa)
, Michal ŠkopJednou ze základních vizualizací jsou choropletové mapy. Ukážeme si, jak sestrojit takovou mapu ČR za pomoci otevřených dat a open source nástrojů.
V češtině jsou trochu nešťastně zvané kartogramy (neboť cartogram v angličtině a mnoha jiných jazycích je něco jiného).
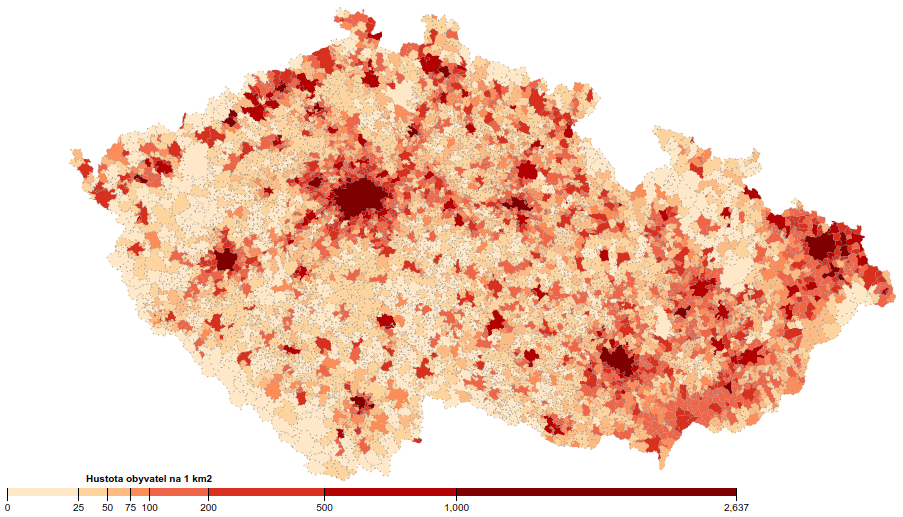
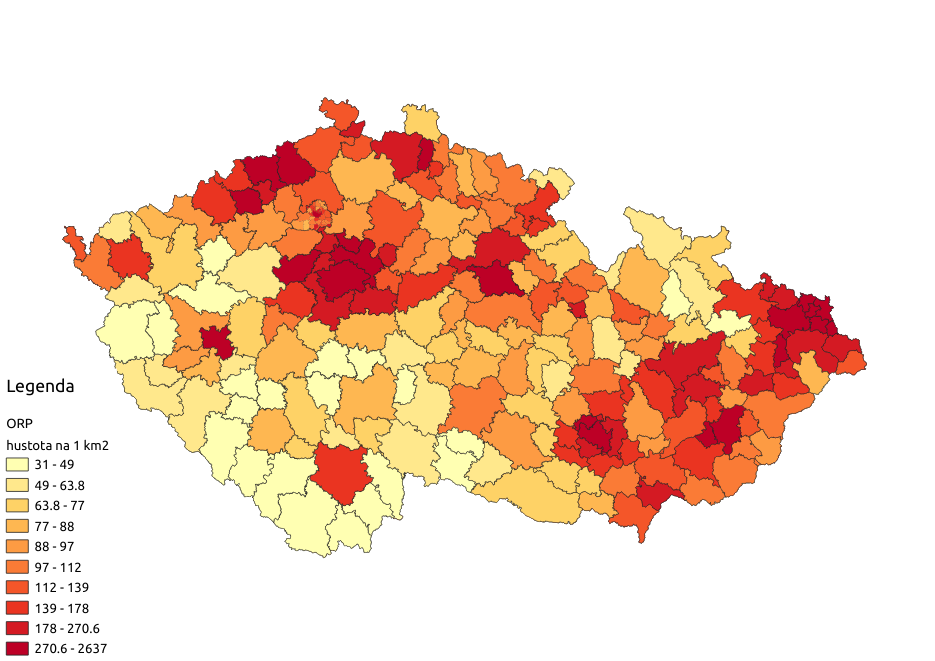
Zobrazení v mapách: Obce a ORP v ČR - hustota obyvatel
Cílem je zhotovit takovouto mapu zobrazující hustotu zalidnění v obcích a obdobnou v ORP (“malé okresy”) v ČR. Hustota zalidnění je tu zvolená na ukázku, stejně tak lze zobrazit leccos jiného.
Zkusíme tu více postupů, jak se k výsledné mapě dostat:
- pomocí javascriptové knihovny D3
- v GISovém programu QGIS
Samozřejmě je těch možných postupů mnohem více, např. pomocí package RCzechia v R.
Použitá data
Data použitá pro tento projekt si najdeme v NKOD - Národním katalogu otevřených dat.
-
Pro geografickou část použijeme data z RÚIANu od ČÚZK: RUIAN Stát - SHP.
-
Pro data o počtu obyvatel a rozloze území použijeme data ČSÚ: Statistická data pro územně analytické podklady.
Instalace potřebných programů
Pro přípravu dat pro D3 si naistalujeme potřebné programy, které jsou open source a zdarma: ndjson-cli, topojson-server, topojson-simplify, topojson-client, shapefile, d3-tsv (možná je třeba užít sudo):
npm install ndjson-cli
npm install topojson-server
npm install topojson-simplify
npm install topojson-client
npm install shapefile
npm install -g d3-dsv # note: this did not work without the -g
Pro přípravu dat a pro vykreslení v QGISu potřebujeme samozřejmě nainstalovat QGIS, který je open source a zdarma.
Postup zpracování: Mapa v D3
Příprava dat
Standardizace geodat
Z RÚIANu si stáhneme data a ze souboru 1.zip extrahujeme do svého pracovního adresáře všechny soubory začínající OBCE_P (obce) a ORP_P (ORP).
Tyto SHP soubory mají zatím několik problémů:
- Nejsou v kódování UTF-8, ale v českém Win-1250
- Jsou ve speciálním česko-slovenském souřadnicovém systému S-JTSK a ne v daleko běžnějším WGS 84.
Oba tyto problémy pořešíme projednou ručně - v LibreOffice a v QGISu. Jiné postupy pro geo-kódování jsou navržené třeba zde, příp. kódování češtiny lze řešit i v QGISu, jak je popsáno zde.
UTF-8:
- Otevřeme
OBCE_P.dbfvLibreOffice Calcu(vybereme kódováníEastern Europe (Windows-1250/WinLatin2) - Dáme
File->Save As..., zvolíme opětOBCE_P.dbfa vlevo dole zaškrtnemeEdit filter settings. - Zvolíme kódování
Unicode (UTF-8)a uložíme.
WGS 84:
-
Otevřeme
OBCE_P.shpvQGIS. - V Panelu
Layerskliknutím pravým naOBCE_Potevřeme kontextové menu, dámeExport->Save Features As .... - Zadáme
File namejako<pracovní adresář>/obce.shpa jakoCRSdámeWGS 84a uložíme.
Podobně si přetransformujeme i ORP do souborů <pracovní adresář>/orp.shp (a další orp. se vytvoří).
Příprava statistických dat
Z ČSÚ stáhneme data a extrahujeme do svého pracovního adresáře soubor UAP01_2018 (příp. novější rok). Z něj vyfiltrujeme (opět např. ručně v LibreOffice Calc) řádky, které v sloupci vuk_txt mají hodnoty Celková výměra (v hektarech) a Počet obyvatel. A vytvoříme si nový soubor <pracovní adresář>/obce_hustota.csv, a dopočteme si hustotu zalidnění na 1 km2. Vyplatí se nám původní soubor nejprve seřadit dle vuk_txt a uzemi_kod (což je kód obce). Můžeme se vyhnout některým možným problémům při zobrazování dat v budoucnu, pokud tu hustotu zaokrouhlíme (tj. =round(počet obyvatel / výměra * 100)). Tabulka bude vypadat nějak takto, pro budoucí potřeby si kód obce (uzemi_kod) označíme jako id (budeme potřebovat slupce id a hustota):
| id | Celková výměra (v hektarech) | Počet obyvatel | hustota | uzemi_txt |
|---|---|---|---|---|
| 500011 | 1603 | 1865 | 116 | Želechovice nad Dřevnicí |
| 500020 | 1209 | 1224 | 101 | Petrov nad Desnou |
| … | … | … | … | … |
Např. pomocí Pivot tables (Kontingenční tabulky) rovnou v LibreOffice Calc (Insert->Pivot Table...) si vytvoříme obdobný soubor orp_hustota.csv, kde budeme mít minimálně prislorp_kod a vypočtený sloupec hustota.
Bohužel kódy ORP v těchto datech a datech z RÚIANu nejsou shodné, tak je ještě musíme sjednotit. Takže opět použijeme Národní katalog otevřených dat a najdeme si Číselník obcí s rozšířenou působností. Přímo se nám nabízí stažení jenom v XML, což by znamenalo další práci navíc. Naštěstí NKOD má odkaz i na zdrojovou stránku s dokumentací (Zobrazit dokumentaci) a na této stránce skočíme na Ke stažení a tady už si můžeme vybrat i formát CSV. Dáme stáhnout a máme soubor CIS0065_CS.csv.
Z toho nás zajímají sloupce CHODNOTA (alias kód ORP dle ČSÚ) a KOD_RUIAN (alias kód ORP dle RÚIANu).
A upravíme náš finální soubor orp_hustota.csv do takovéhoto stavu, kde id je přejmenovaný KOD_RUIAN.
| id | Celková výměra (v hektarech) | Počet obyvatel | hustota | prislorp_txt | prislorp_kod |
|---|---|---|---|---|---|
| 19 | 49621 | 1308632 | 2637 | Praha | 1000 |
| 27 | 1209 | 1224 | 88 | Benešov | 2101 |
| … | … | … | … | … | … |
Tranformace z SHP do TopoJSONu
Pro použití v D3 potřebujeme přetransformovat data z formátu SHP. Půjdeme zde hlavně podle tutoho tutoriálu od autora knihovny D3 Mike Bostocka.
Během tohoto postupu budeme také chtít zjednodušit hranice území. Je to proto, že jsou z RÚIANu příliš podrobné pro naše účely a tím pádem je ten soubor dost velký (obce.shp má 85 MB).
Transformace SHP -> geo(ND)JSON (Newline Delimited JSON) + přidáme KOD (území) jako naše id:
cd <náš pracovní adresář>
shp2json -n --encoding=utf-8 obce.shp | ndjson-map 'd.id = d.properties.KOD, d' > obce.ndjson
shp2json -n --encoding=utf-8 orp.shp | ndjson-map 'd.id = d.properties.KOD, d' > orp.ndjson
Transformace geo(ND)JSON -> TopoJSON už nám zmenší velikost souboru sama o sobě (obce.ndjson má 208 MB, obce-topo.json jen 108 MB bez ztráty informace):
geo2topo -n tracts=obce.ndjson > obce-topo.json
geo2topo -n tracts=orp.ndjson > orp-topo.json
Zjednodušíme hranice obcí a ORP. Parametr P vyzkoušíme tak, aby se nám to zdálo tak akorát pro požadované použití (čím nižší, tím více zjednodušené hranice a menší soubory), zde použijeme 0.05:
toposimplify -P 0.05 -f < obce-topo.json > obce-simple-topo.json
toposimplify -P 0.05 -f < orp-topo.json > orp-simple-topo.json
Vrátíme zpátky do geo(ND)JSONu (protože tento formát poté použijeme na spojení se statistickými daty):
topo2geo < obce-simple-topo.json tracts=obce-simple.json
ndjson-split 'd.features' < obce-simple.json > obce-simple.ndjson
topo2geo < orp-simple-topo.json tracts=orp-simple.json
ndjson-split 'd.features' < orp-simple.json > orp-simple.ndjson
Statistická data přetransformujeme do NDJSONu:
csv2json -n obce_hustota.csv > obce_hustota.ndjson
csv2json -n orp_hustota.csv > orp_hustota.ndjson
Spojíme geo a statistická data:
ndjson-join --left 'd.id' obce-simple.ndjson obce_hustota.ndjson | ndjson-map 'Object.assign(d[0], Object.assign(d[0].properties, d[1]))' > obce-simple-data.ndjson
ndjson-join --left 'd.id' orp-simple.ndjson orp_hustota.ndjson | ndjson-map 'Object.assign(d[0], Object.assign(d[0].properties, d[1]))' > orp-simple-data.ndjson
Přetransformujeme je z geoNDJSONu do geoJSONu:
cat obce-simple-data.ndjson | ndjson-reduce 'p.features.push(d), p' '{type: "FeatureCollection", features: []}' > obce-simple-data.json
cat orp-simple-data.ndjson | ndjson-reduce 'p.features.push(d), p' '{type: "FeatureCollection", features: []}' > orp-simple-data.json
A konečně je přetransformujeme do TopoJSONu, které použijeme pro samotné mapy:
geo2topo tracts=obce-simple-data.json > obce-simple-data-topo.json
geo2topo tracts=orp-simple-data.json > orp-simple-data-topo.json
Mapa - zobrazení
Na zobrazení mapy potřebujeme webový server, jedna možnost je spustit si ho v našem adresáři pomocí:
cd <náš pracovní adresář>
python3 -m http.server 80
Na adrese localhost v prohlížeči už můžeme sledovat, jak mapu vytváříme (nezapomínáme reloadovat).
Vytvoříme kostru našeho souboru <pracovní adresář>/index.html, kam vložíme potřebné skripty k D3 a základní <svg> element, do kterého mapu vykreslíme:
<!DOCTYPE html>
<html lang="cs">
<meta charset="utf-8" />
<svg width="960" height="520"></svg>
<script src="https://d3js.org/d3.v4.min.js"></script>
<script src="https://d3js.org/d3-scale-chromatic.v1.min.js"></script>
<script src="https://d3js.org/topojson.v2.min.js"></script>
<script>
var svg = d3.select("svg"),
width = +svg.attr("width"),
height = +svg.attr("height");
// sem budeme přidávat další kód
</script>
</html>
Zobrazíme naše připravená data (v TopoJSON) co nejjednodušeji. Použijeme projekci Mercator. Přidáme:
var projection = d3.geoMercator()
.translate([width / 2, height / 2]) // posuneme do středu SVG
var path = d3.geoPath()
.projection(projection);
// sem potom přidáme barvu
// sem potom přidáme měřítko
d3.json("obce-simple-data-topo.json", function(error, data) {
if (error) throw error;
var subunits = topojson.feature(data, data.objects.tracts) // obce
// vykreslíme obce
svg.selectAll(".subunit")
.data(subunits.features)
.enter().append("path")
.attr("d", path)
});
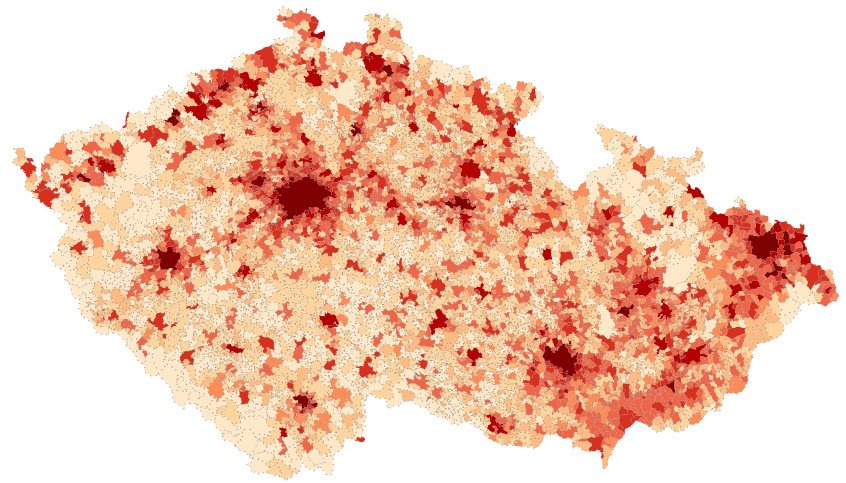
A dostaneme první mapu, něco takovéhoto:

Zvětšíme ji a vycentrujeme na střed ČR (zhruba 49.75N, 15.34E)
var projection = d3.geoMercator()
.center([15.34, 49.75]) //střed ČR
.scale(7000) // měřítko, nastavíme dle potřeb
.translate([width / 2, height / 2]) // posuneme do středu SVG

Obarvíme obce dle hustoty:
// měřítko - barevná škála
// nejmenší hustota v obcích je 0 (volenské újezdy), největší 2637 v Praze
var color = d3.scaleThreshold()
.domain([0, 25, 50, 75, 100, 200, 500, 1000, 2637])
.range(d3.schemeOrRd[9]);
d3.json("obce-simple-data-topo.json", function(error, data) {
if (error) throw error;
var subunits = topojson.feature(data, data.objects.tracts) // obce
// vykreslíme obce
svg.selectAll(".subunit")
.data(subunits.features)
.enter().append("path")
.attr("class", function(d) { return "subunit " + d.id; })
.attr("fill", function(d) { return color(d.properties.hustota); })
.attr("stroke", "#888")
.attr("stroke-dasharray", "1,5")
.attr("stroke-linejoin", "round")
.attr("d", path)
});
Přidáme měřítko - legendu:
var x = d3.scaleSqrt()
.domain([31, 2637])
.rangeRound([100, 750]);
var g = svg.append("g")
.attr("class", "key")
.attr("transform", "translate(0,490)");
g.selectAll("rect")
.data(color.range().map(function(d) {
d = color.invertExtent(d);
if (d[0] == null) d[0] = x.domain()[0];
if (d[1] == null) d[1] = x.domain()[1];
return d;
}))
.enter().append("rect")
.attr("height", 8)
.attr("x", function(d) { return x(d[0]); })
.attr("width", function(d) { return x(d[1]) - x(d[0]); })
.attr("fill", function(d) { return color(d[0]); });
g.append("text")
.attr("class", "caption")
.attr("x", x.range()[0])
.attr("y", -6)
.attr("fill", "#000")
.attr("text-anchor", "start")
.attr("font-weight", "bold")
.text("Hustota zalidnění na 1 km2");
g.call(d3.axisBottom(x)
.tickSize(13)
.tickValues(color.domain()))
.select(".domain")
.remove();
A máme výslednou mapu hustoty zalidnění v obcích ČR:
Jenom změníme vstupní soubor orp-simple-data-topo.json na orp-simple-data-topo.json, upravíme měřítko (nejmenší hustota v ORP je 31) a máme i mapu dle ORP:
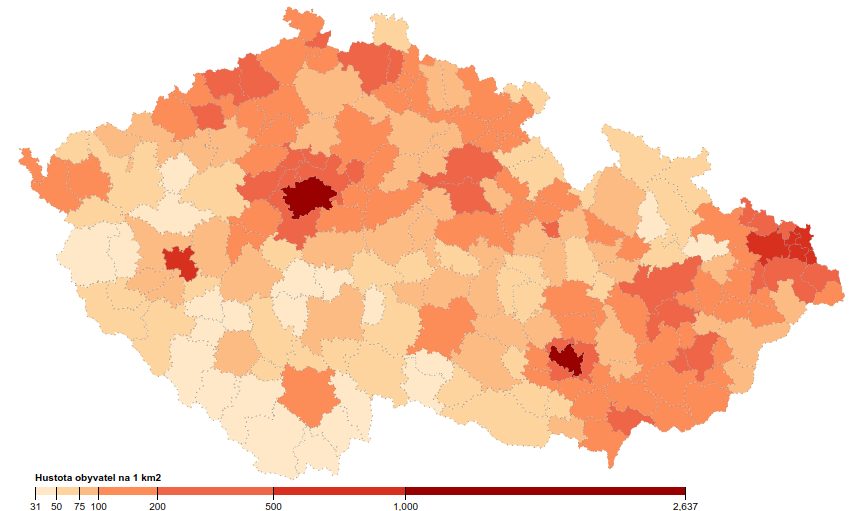
Postup zpracování: Mapa v QGIS
Jako vstupní použijeme připravené soubory obce.shp (a jím odpovídající soubory obce.) a obce_hustota.csv (+ orp.shp a orp_hustota.csv) - dle postupu popsaném k D3.
Ještě si připravíme (např. v Notepadu, Geditu, Atomu, apod.) jeden soubor v našem pracovním adresáři: obce_hustota.csvt. V něm jsou typy proměnných u sloupců v obce_hustota.csv. Pokud máme např. v obce_hustota.csv sloupce id, Celková výměra (v hektarech), Počet obyvatel, hustota a uzemi_txt, tak bude soubor obce_hustota.csvt vypadat následovně:
"String","String","String","Integer","String"
A obdobně vytvoříme soubor orp_hustota.csvt.
Otevřeme obce.shp v QGISu. Změníme projekci na lepší pro ČR: V dialogu Project Properties (úplně vpravo, nikoliv vlevo, dole) nastavíme EPSG:32633.
Přidáme data o hustotě: Layer->Add Layer->Add Vector Layer ... vybereme <pracovní adresář>/obce_hustota.csv.
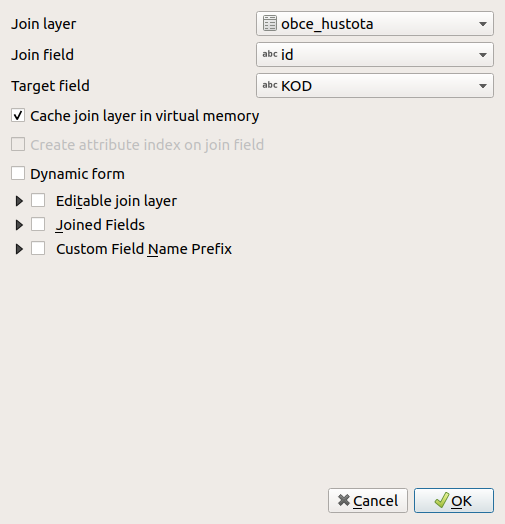
V kontextovém menu u Layers - obce (pravým tlačítkem myši) vybereme Properties... a dostaneme dialog Layer Properties. Vybereme Joins a přidáme (Tlačítko +) nový Join, spojíme id s KOD, neboli připojíme data o hustotě k mapě.
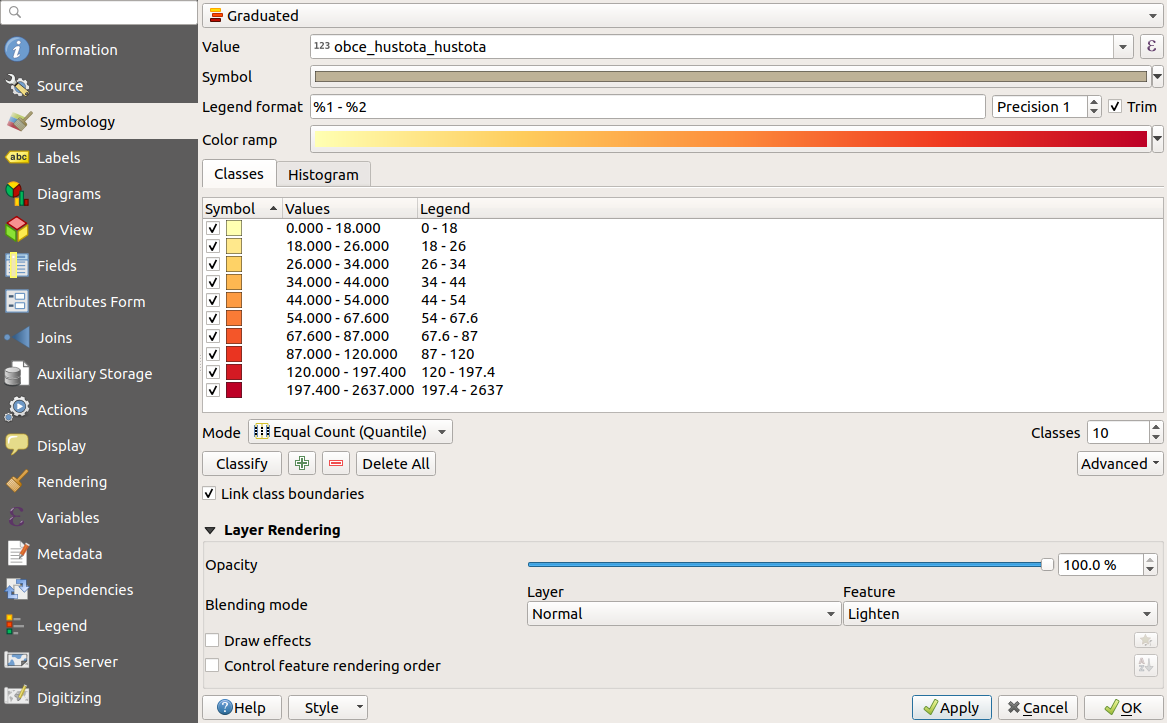
V Layer Properties teď vybereme Symbology a jdeme obarvovat mapu dle hustoty. Např. takto:
Teď už nám chybí jenom připravit jako obrázek (pokud nechceme rovnou udělat screenshot) a přidat legendu.
Vytvoříme nový Layout: Project->Layout Manager .... Odklikáme a máme nové okno Layout 1.
V tomto okně Add Item->Add Map a myší označíme celou tu připravenou stránku. A mápe mapu v Layoutu. Přidáme legendu Add Item->Add Legend a myší zase označíme, kam ji chceme. Jsme v zhruba takovémto stavu:
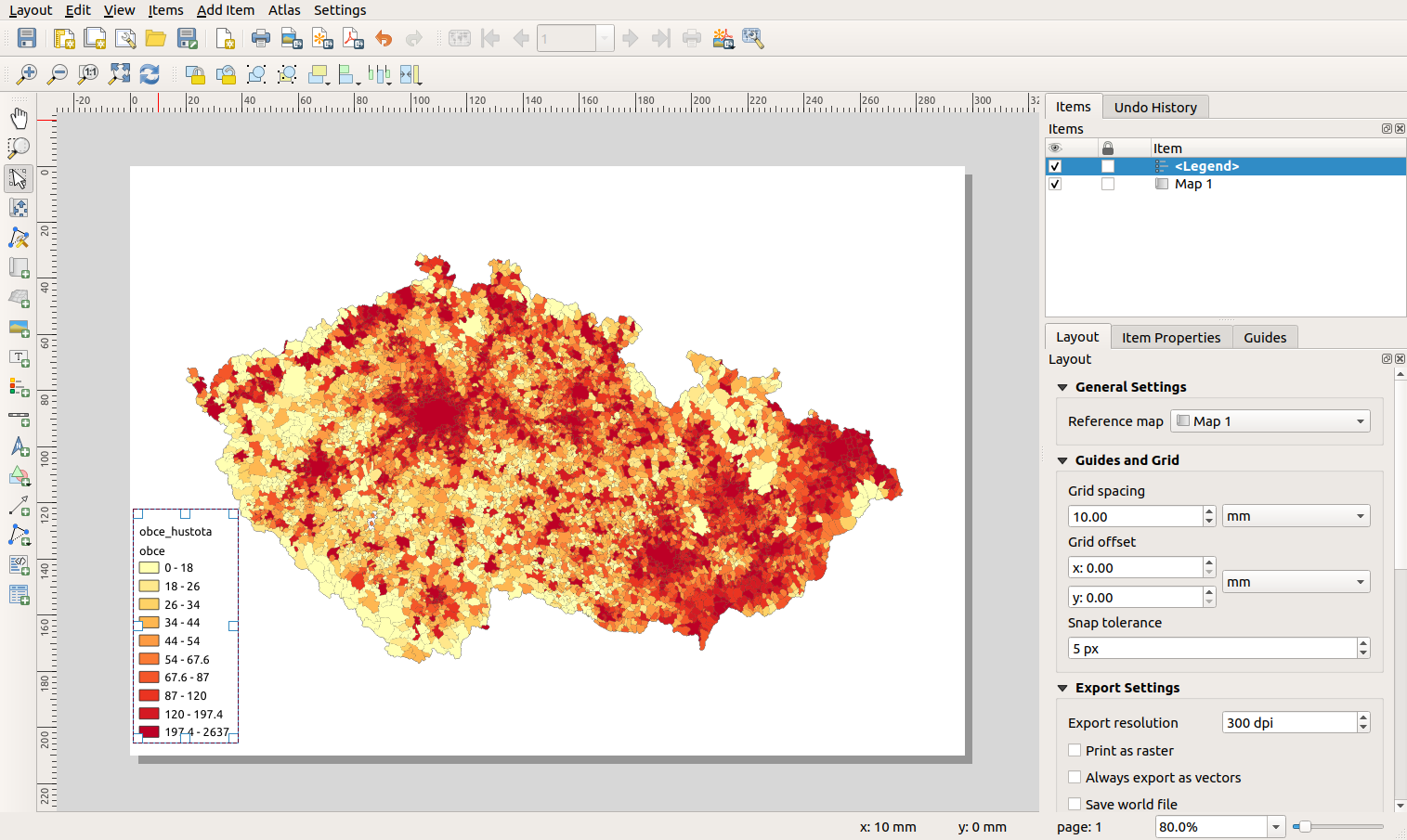
Legendu si můžeme doupravit (pravým v Layoutu legendy: Item properties ...) dle svého.
Výsledek si můžeme vyexportovat v SVG nebo PNG, …, např. Layout->Export as Image...

A obdobně bychom mohli udělat mapu pro ORP.
Použité soubory
- index.html
- obce_hustota.csv
- obce_hustota.csvt
- obce-simple-data-topo.json
- orp_hustota.csv
- orp_hustota.csvw
- orp-simple-data-topo.json
Další užití
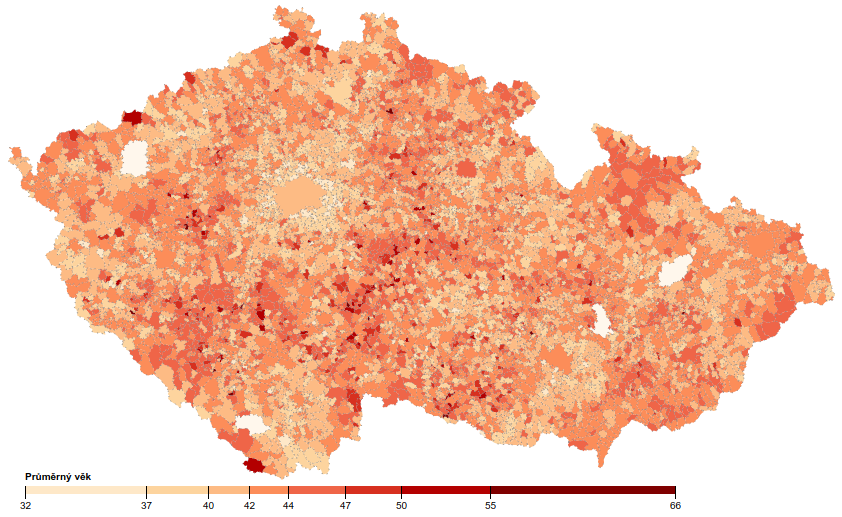
Obdobně se dají zobrazit další a další mapy, např. zde zcela stejných postupem vytvořená mapa průměrného věku v obcích ČR:
GeoJSONy a TopoJSONy ČR
Připravené a zjednodušené soubory dle postupu výše, stav duben 2020, WGS 84
- Katastrální území: katastralni_uzemi-simple.json, katastralni_uzemi-simple-topo.json
- Volební okrsky: volebni_okrsky-simple.json, volebni_okrsky-simple-topo.json
- Obce: obce-simple.json, obce-simple-topo.json
- Stavební úřady: stavebni_urady-simple.json, stavebni_urady-simple-topo.json
- Pověřené obecní úřady: poverene_obecni_urady-simple.json, poverene_obecni_urady-simple-topo.json
- ORP: orp-simple.json, orp-simple-topo.json
- Regiony soudržnosti: regiony_soudrznosti-simple.json, regiony_soudrznosti-simple-topo.json
- Kraje: kraje-simple.json, kraje-simple-topo.json
- Regiony (NUTS 2): regiony-simple.json, regiony-simple-topo.json
- ČR: cr-simple.json, cr-simple-topo.json
Použité nástroje a zdroje:
D3
- California Population Density - Michael Bostock
- Tutoriál Command-Line Cartography - Michael Bostock
- Tento tutoriál zjednodušeně v Observable
- TopoJSON-simplify
- NDJSON-CLI
- TopoJSON-client
- TopoJSON-server
- Streming Shapefile Parser